Keyword Spotting
Keyword Spotting is a powerful and fast technology designed to help you identify specific words in audio recordings. It supports 25 languages and lets you create custom keyword lists with words that may have one or more pronunciations.
Have a look at the complete language portfolio of our Keyword Spotting.
This page explains how to use Phonexia Keyword Spotting in our web application. If you want to dive deeper into the inner workings of this technology, check out our detailed technical documentation.
Uploading files
Upload your files or create your own recordings by using the built-in recording feature. If you don't have your own files, you can use the provided Phonexia examples to explore how the technology works. As mentioned above, if you choose to use our example recordings, a predefined keyword list will be used for processing. Learn more about uploading files here.
Files can also be sent to and received from other Phonexia technologies. Learn more about sending files here.
Creating a keyword list
Unless you want to try out Keyword Spotting using Phonexia’s example recordings with a predefined keyword list, your first step is to create a new keyword list.
- Click "Create new" in the drop-down panel that appears in the first input field.
- Choose the language you will be working with.
- Start adding keywords. You can only use graphemes (letters) allowed for the selected language.
Once you enter a word, the language of the keyword list cannot be changed, as the grapheme and phoneme sets are language-specific.
- Add pronunciation (optional) by clicking the plus button. Clicking the keyboard icon, a phoneme keyboard for the chosen language will appear on the right, making it easier to enter pronunciations manually. While hovering over a phoneme in the phoneme keyboard, a tooltip will show example words that use that phoneme.
Adding pronunciations is recommended for greater precision — especially when dealing with non-standard words, shortcuts, acronyms, abbreviations, specific dialects, or jargon. If you’d like to explore the supported graphemes and phonemes in more detail, including additional word examples and their phonemic representations, you can visit this documentation page.
- Save your keyword list.
Results
After uploading your recordings, they will be listed in the left panel.
Leaving the page for an extended period while awaiting the results may interrupt the process. If this happens, you will need to restart the audio processing.
Once processing is complete, the results for each recording will be displayed in the right panel. Each occurrence is shown with a timestamp and confidence score, along with a play icon that lets you listen to the detected segment.
By default, only words with a confidence score above 50% are displayed to minimize false positives. You can adjust this threshold at any time using the control in the upper right corner of the panel.
Export formats
Once your results are ready, you can export them in various formats.
Keyword Spotting results can be exported individually for each audio file in CSV, XLSX, or JSON format. Each export file is named after the corresponding recording and includes metadata such as: channel number, timestamp, keyword, specific pronunciation of the occurrence, pronunciation source and confidence score. The same results can also be exported in bulk as a ZIP file.
There are three sources of pronunciation. While they are not shown directly in the web application results, they are included in each export file.
- user – manually added by the user
- dictionary – automatically added if the word is found in Phonexia’s curated and verified internal dictionary
- generated – automatically generated by the built-in grapheme-to-phoneme converter
XLSX format
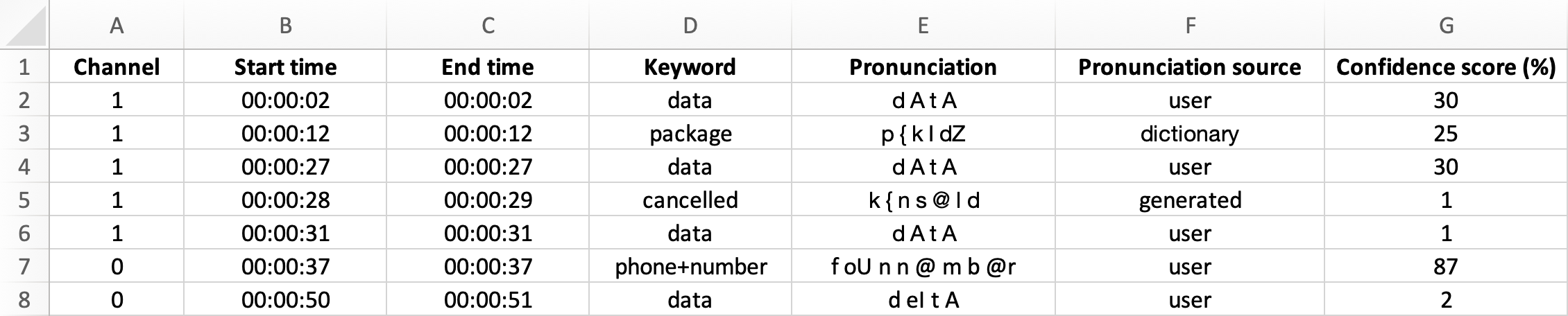
CSV format
Channel,Start time,End time,Keyword,Pronunciation,Pronunciation source,Confidence score (%)
1,2.02,2.23,data,d A t A,user,30
1,12.22,12.55,package,p { k I dZ,dictionary,25
1,27.20,27.68,data,d A t A,user,30
1,28.70,29.16,cancelled,k { n s @ l d,generated,1
1,31.11,31.32,data,d A t A,user,1
',37.34,37.85,phone+number,f oU n n @ m b @r,user,87
0,50.98,51.44,data,d eI t A,user,2
JSON format
{
"matches": [
{
"channel_number": 1,
"start_time": 2.02,
"end_time": 2.23,
"confidence": 0.0139,
"keyword": {
"spelling": "data",
"pronunciation": "d A t A",
"pronunciation_source": "user"
}
},
{
"channel_number": 1,
"start_time": 12.22,
"end_time": 12.55,
"confidence": 0.0127,
"keyword": {
"spelling": "package",
"pronunciation": "p { k I dZ",
"pronunciation_source": "dictionary"
}
},
{
"channel_number": 1,
"start_time": 31.105,
"end_time": 31.315,
"confidence": 0.005,
"keyword": {
"spelling": "data",
"pronunciation": "d A t A",
"pronunciation_source": "user"
}
},
{
"channel_number": 1,
"start_time": 61.435,
"end_time": 62.005,
"confidence": 0.00033,
"keyword": {
"spelling": "phone+number",
"pronunciation": "f oU n n @ m b @r",
"pronunciation_source": "user"
}
},
{
"channel_number": 1,
"start_time": 62.575,
"end_time": 63.025,
"confidence": 0.01465,
"keyword": {
"spelling": "cancelled",
"pronunciation": "k { n s @ l d",
"pronunciation_source": "generated"
}
}
]
}