Gender Identification
Phonexia Gender Identification is an advanced technology designed to accurately determine if the speaker is male or female, that is, whether a voice is masculine or feminine, within an audio recording, regardless of the language spoken.
This page explains how to use Phonexia Gender Identification in our web application. If you want to dive deeper into the inner workings of this technology, check out our detailed technical documentation.
Uploading files
Upload your files or create your own recordings by using the built-in recording feature. In addition to standard media files, gender identification can also process voiceprints. If you don't have your own files, you can use the provided Phonexia examples to explore how Gender Identification works. Learn more about uploading files here.
Files can also be sent to and received from other Phonexia technologies. Learn more about sending files here.
Results
After uploading, your recordings will appear in the left panel.
Leaving the page for an extended period while awaiting the results may interrupt the process. If this happens, you will need to restart the audio processing.
Once processing is complete, the results for each recording will be displayed in the right panel as a radial bar chart that indicates the speaker's gender, using blue for female and turquoise for male. For stereo audio, two results will be shown—one for each channel.
You can always play your audios, but if you use voiceprints, the player will be inactive since they cannot be played. Additionally, no channel specification will be displayed for voiceprints.
Keep in mind that the result is always between 50% and 100%. A probability value below 50% would indicate the opposite gender (male to female or vice versa). Therefore, if the result is, for example, 54% male, it suggests a low level of certainty about the speaker's gender, indicating it is close to female.
A low probability value can be caused by several factors:
- The voice is challenging to classify as either male or female.
- The processed channel or voiceprint contains more than one speaker of both genders. For optimal results, ensure there is only one speaker per channel.
Export formats
Once your results are ready, you can export them in various formats.
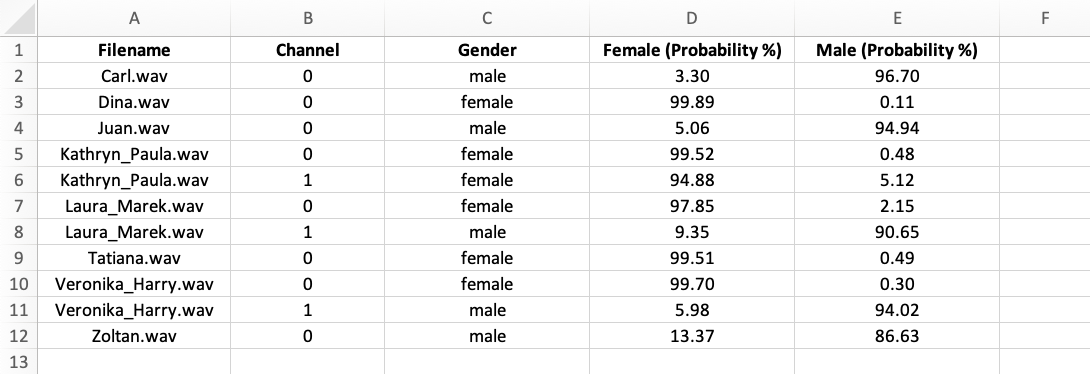
Gender Identification results can be exported individually for each file in CSV, XLSX, or JSON format. Each export file is named after the corresponding file and includes the channel number (if it is not a voiceprint), along with the detected gender and confidence level.
The same results can also be exported in bulk as a ZIP file. Additionally, users have the option to export a summary file that displays the scores for all the selected recordings.
XLSX

CSV
Channel,Gender,Female (Confidence %),Male (Confidence %)
0,female,0.98,0.02
1,male,0.09,0.91
JSON
While JSON-format results for audio include channel information, speech length, and probabilities, results for voiceprints only display speech length and probabilities.
- Audio File
- Voiceprint
{
"channels": [
{
"channel_number": 0,
"speech_length": 34.64,
"scores": {
"male": {
"probability": 0.92574
},
"female": {
"probability": 0.07426
}
}
}
]
}
{
"voiceprint_scores": [
{
"speech_length": 34.64,
"scores": {
"male": {
"probability": 0.92574
},
"female": {
"probability": 0.07426
}
}
}
]
}
All results
Whether in CSV or XLSX format, the export file displays the detected gender and the confidence level for both male and female genders in the recording.