Speaker Identification
Phonexia Speaker Identification (SID) uses the power of voice biometrics to recognize speakers by their voice, determining whether the voice in two recordings belongs to the same person or two different people. Our goal as a regular participant of the NIST Speaker Recognition Evaluations (SRE) series is to contribute to the advancement of research efforts and the calibration of technical capabilities in text-independent speaker recognition. The objective is to boost the technology and identify the most promising algorithmic approaches for our future production-grade solutions.
Use cases and application areas
The technology can be used for various speaker recognition tasks. One basic distinction is based on the kind of question we want to answer.
Speaker Identification addresses the question “Whose voice is this?”, such as in the case of fake emergency calls. Usually, this entails one-to-many (1:n) or many-to-many (n:n) comparisons.

Speaker Search helps find out “Where is this voice speaking?”, such as when looking for a speaker inside a large archive.
We use Speaker Spotting when monitoring a large number of audio recordings or streams and looking for the occurrence of a specific speaker(s). Speaker spotting can be deployed for the purpose of Fraud Alert.
Speaker Verification answers the question “Is this Peter Smith’s voice?”, such as when a person calls the bank and says, “Hello, this is Peter Smith!”. This approach of one-to-one (1:1) verification is also employed in Voice-As-a-Password systems, which can add further security to multi-factor authentication over the telephone.

Large-scale automatic speaker identification is also successfully used by law enforcement agencies during investigations for the purposes of database searches and ranking of suspects. In later stages of a case, Forensic Voice Analysis uses smaller amounts of data and 1:1 comparisons to evaluate evidence, establish the probability of the identity of a speaker, and use it in court.
How does it work?
The technology is based on the fact that the speech organs and speaking habits of every person are more or less unique. As a result, the characteristics (or features) of the speech signal captured in a recording are also more or less unique. Consequently, the technology can be language-, accent-, text-, and channel-independent.
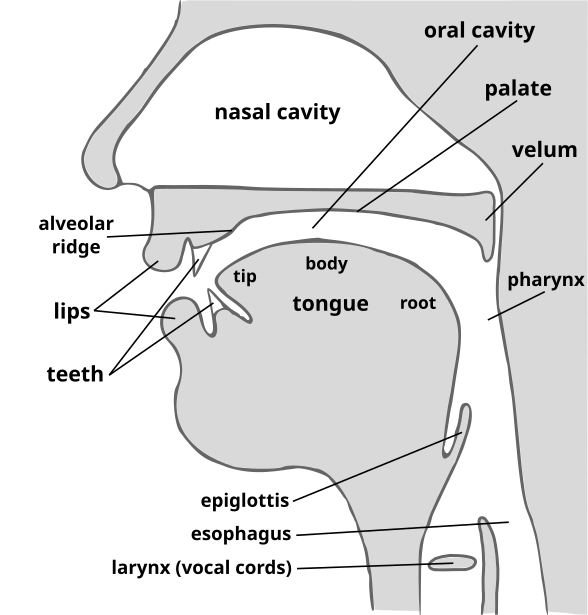
Automatic speaker recognition systems are based on the extraction of unique features from voices and their comparison. The systems thus usually comprise two distinct steps: Voiceprint Extraction (Speaker enrollment) and Voiceprint comparison.
Voiceprint extraction is the most time-consuming part of the process. Voiceprint comparison, on the other hand, is extremely fast – millions of voiceprint comparisons can be done in 1 second.
Voiceprint
A voiceprint (also known as x-vector) is a fixed-length matrix that captures the most unique characteristics of a speaker’s voice. Voiceprints are unique to each individual, similar to fingerprints or retinal scans.
Voiceprint file
The internal structure of the voiceprint consists of a header (metadata information) and a data part that contains characteristics of the speaker's voice. The structure and length of a voiceprint are always the same, regardless of the length and number of the source recordings. A voiceprint created from a single short recording will always be the same size as a voiceprint created from 80 different long recordings. The exact number of digits may vary depending on the technology model selected.
What can be learned from a voiceprint?
- Similarity to another voiceprint
- Speaker’s gender
- Total length of original recordings
- Amount of speech used for voiceprint extraction
What cannot be learned from a voiceprint?
The most important feature of Phonexia Speaker Identification technology is that it prevents the retrieval of the audio source, call content, or original voice sound from a voiceprint. The voiceprint file only contains statistical information about the unique characteristics of the voice, without including information that could be used to reconstruct the audio contents (i.e., who said what) or for voice synthesis systems (TTS - Text to Speech).
Backward compatibility
Previously, a voiceprint created by a Speaker Identification model could only be used with that specific model. For instance, it was not possible to compare a voiceprint created by the XL3 model with the XL4 model. However, XL5 offers backward compatibility, allowing it to generate voiceprints that can be compared with XL4 voiceprints.
This capability is enabled because XL5 voiceprint extraction produces two subvoiceprints: a new XL5 voiceprint and an XL4-compatible voiceprint (though not identical to XL4)."
- XL4 voiceprints cannot be converted to XL5, but it is possible to compare XL5 and XL4 voiceprints using the XL5 comparator if XL5 voiceprints have been extracted in compatibility mode.
- XL5 voiceprints extracted in compatibility mode are only comparable with XL4 voiceprints; comparison with older voiceprint generations (L4, XL3, L3, etc.) is not supported.
- Compatibility mode is turned off by default.
Voiceprint encoding
Although the information conveyed by the voiceprint is identical in both microservices and Virtual appliance, the way this information is represented, that is, its encoding, differs.
The format used for Virtual appliance is Base64. This is because the format for REST API calls and responses is JSON. JSON is a text-based format that can directly handle text or numerical data only. Therefore, voiceprints, which are binary data, need to be converted. The most common method for encoding binary data in JSON is Base64 encoding.
In contrast, the gRPC API can directly handle binary data. Therefore in the case of microservices, the encoding used is UBJSON (Universal Binary JSON).
Regardless of how the voiceprint is encoded, there is no need to decode it. Users can store the encoded voiceprint for later comparison. Decoding and re-encoding would unnecessarily consume resources.
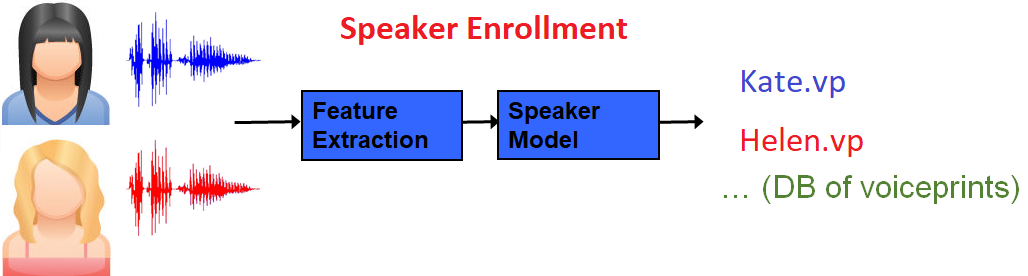
Voiceprint extraction (Speaker enrollment)
Speaker enrollment starts with the extraction of acoustic features from a recording of a known speaker. The process continues with the creation of a speaker model which is then transformed into a small but highly representative numerical representation called a voiceprint. During this process, the SID technology applies state-of-the-art channel compensation techniques.
Voiceprint comparison
Any voiceprint of an unknown speaker can be compared with existing enrollment voiceprints and the system returns a score for each comparison.
Scoring and conversion to percentage
The score produced by comparing two voiceprints is an estimate of the probability (P) that we would obtain the given evidence (the compared voiceprints) if the speakers in the two voiceprints are the same or different individuals. The ratio between these two probabilities is called the Likelihood Ratio (LR), often expressed logarithmic form as Log Likelihood Ratio (LLR).
Transformation to confidence (or percentage) is usually done using a sigmoid function:
where:
shiftshifts the score to be 0 at ideal decision point (default is 0)sharpnessspecifies how the dynamic range of score is used (default is 1)
The shift value can be obtained by performing a proper SID evaluation – see
the chapter below for details.
The sharpness value can be chosen
according to the desired steepness of the sigmoid function:
- a higher sharpness means steeper function, indicating a sharper transition between lower and higher percentages, with only small differences in the low and high percentages;
- a lower sharpness means less steep function, resulting in more linear transition.
The interactive graph below should help you understand the correlation between score and confidence, influenced by the steepness of the sigmoid function controlled by the sharpness value.
Domain adaptation
In real-world applications, speaker identification systems often encounter audio recordings captured in domains different from those used for training. These domains may vary in factors such as microphone quality, recording environment, or audio codecs. Such domain mismatches can significantly impact speaker identification accuracy.
To address this challenge, our system utilizes domain adaptation techniques. Domain adaptation aims to bridge the gap between the training and target data distributions, enabling the system to learn unseen speaker representations and generalize effectively to new domains. Compared to fine-tuning, domain adaptation offers the advantage of requiring significantly less training data.
Our system is primarily trained on telephony and VoLTE recordings. To enhance its accuracy on diverse data types, we employ domain adaptation trained on datasets from various sources, including YouTube, Skype, WhatsApp, and satellite recordings. This adaptation is encapsulated in adaptation profiles. Currently, these profiles are embedded into our models and cannot be configured or customized by users.
The most suitable adaptation profile for a given voiceprint is selected based on its similarity to the adaptation profiles. The selected adaptation profile is applied during voiceprint comparison and does not impact voiceprint extraction in any way. However, future introduction of new adaptation profiles into the model may result in slight variations in voiceprint comparison scores, even for training domain data. This effect is minimal and does not compromise the system's accuracy on familiar domains, but rather improves its performance on new ones.