Speech Platform 3
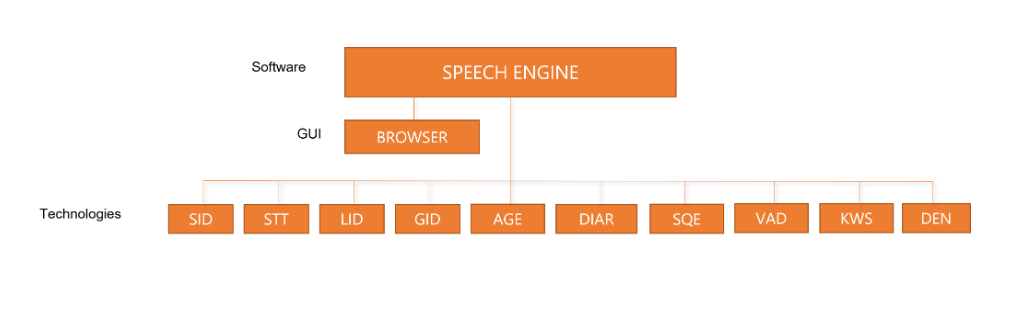
Phonexia Speech Platform (PSP) is an umbrella concept for all Phonexia software components and services related to speech technologies with wide support of languages. It provides the ability to customize various products to a wide range of customer needs.
The Phonexia Speech Platform is provided as a set of several components:
- The Speech Engine (SPE) component is a REST API that includes technologies for the automated processing of audio files and audio streams. This component is usually provided in a specific configuration that meets the customer’s use case.
- The Phonexia Browser component is an expert-level application (on top of the Speech Engine) with a graphical user interface for advanced evaluation.
- The Reporting and Licensing Server (RLS) component is dedicated to limiting the capacities as purchased by a customer (if it is an on-premises deployment without access to the internet) or gathering and calculating the pay-as-you-go amount (if it is a deployment with access to the internet).
Speech Technologies Available
The Speech Platform includes the following technologies. Technologies are available in the Speech Engine component based on its particular configuration (Voice Biometrics, Transcription System, etc.):
- Speaker Identification (SID) – automatically detects a person based on their voice.
- Speaker Diarization (DIAR) – automatically separates multiple speakers in mono audio.
- Language Identification (LID) – detects the language or dialect spoken in a recording.
- Speech to Text (STT) – converts speech into plain text (words or sentences) automatically; several languages supported.
- Keyword Spotting (KWS) – detects specific keywords/phrases automatically without conversion to text; several languages supported.
- Gender Identification (GID) – identifies whether a speaker is male or female.
- Age Estimation (AGE) – estimates the speaker's age group.
- Voice Activity Detection (VAD) – detects the audio part that contains voice.
- Speech Quality Estimation (SQE) – measures the quality of speech.
- Phoneme Recognizer (PHNREC) – converts speech into phonemes (written characters representing pronunciation); several languages supported.
- Waveform Denoiser (DENOISER) – automatically improves the audibility of speech for human listeners.
Supported Languages
The LID, STT, and KWS technologies support various languages as listed in the Languages Available section:
Supported Audio Input
The Speech Engine server supports various audio formats, as listed in the API reference under Audio Requirements.
It also supports RTP/HTTP stream processing, as listed in the API reference under RTP/HTTP Streams.
The Speech Engine allows the use of certain audio conversion tools, such as sox
or ffmpeg. For the configuration of this functionality, see
[SPE]/settings/phxspe.properties.
Note: Be aware that audio format conversion (e.g., if the original audio format is highly compressed) can decrease the accuracy of speech technologies.
Integration Possibilities
The Phonexia Speech Platform can be integrated into a partner’s application using the Speech Engine component (REST API).
Packages, Updates vs. Upgrades
Our packages follow a bug fix > updates > upgrades approach.
The Speech Platform package is available with a typical set of technologies for download here.
Some packages are distributed with a limited set of speech technologies or even without any speech technologies.
Find more information in Packages, Updates vs. Upgrades.
You might also want to browse our product support lifecycle policy to see which versions are supported and maintained.
Capacity/Licensing Options
A partner/customer needs to deploy capacity and licensing files to their
deployment.
Several variants of licensing are available for our partners/customers depending
on the stage of use:
1. Demo/evaluation stage
- Capacity – The user is given a small amount of capacity (usually
capacity.datis copied to the RLS component) to test that the Speech Platform meets their use case. - License – The "NET" license type. The license (usually one
license.datfile copied to all Speech Platform components) is validated on the Phonexia.com licensing server via the internet (no audio is sent to Phonexia).
2. Production stage
This depends on a business agreement with Phonexia, usually one of the following:
- Pay-as-you-go solution (for the commercial market):
- Capacity & license are managed by the RLS component, which calculates the amount processed during a monthly period. The amount is reported by the RLS component (deployed on the customer’s side) to the RLS installed on the Phonexia side. The RLS requires capacity & license for security reasons only.
- Prepaid-amount-per-day solution (for the government market):
- Capacity – The user is given the purchased amount of capacity (usually
capacity.datis copied to the RLS component). - License – The "HW" license type. The license (usually one
license.datfile copied to all Speech Platform components) is bound to a hardware profile of the machine where the Speech Platform is deployed (an offline license).
- Capacity – The user is given the purchased amount of capacity (usually
- Project-based solution:
- For big data-processing solutions, we offer special licensing variants. These are provided on a project basis. Please reach out to your Phonexia contact for more information.
Note: Learn more about Licensing.
Phonexia Speech Engine (SPE)
Phonexia Speech Engine (SPE) is a server application, providing REST API to the entire portfolio of Phonexia speech technologies.
SPE capabilities overview:
| Technology | Audio files | RTP / HTTP streams |
|---|---|---|
| Speaker Identification (SID) | Yes | Yes |
| Speech To Text (STT) | Yes | Yes |
| Keyword Spotting (KWS) | Yes | Yes |
| Voice Activity Detection (VAD) | Yes | Yes |
| Time Analysis Extraction (TAE) | Yes | Yes |
| Speech Quality Estimation (SQE) | Yes | Yes |
| Language Identification (LID) | Yes | No |
| Gender Identification (GID) | Yes | No |
| Age Estimation (AGE) | Yes | No |
| Speaker Diarization (DIAR) | Yes | No |
Results caching - Processing results can be optionally stored in results cache database to speed up eventual re-processing of the same recordings by the same technology – results are then returned immediately from the cache instead of complete re-processing of the audio file.
Own persistent data storage - SPE keeps uploaded audio files in its own persistent storage space, so the original source files can be archived or deleted after upload.
Data privacy - SPE keeps information about audio file or stream only as long as the file or stream exists. Once the recording is deleted from SPE storage, or stream is ended, SPE removes all information, metadata and technology results from the database.
Basic user management - SPE allows the definition of multiple users with different user roles and user rights. Each SPE user has access only to its own data storage, files, metadata and processing results.
Load management - SPE manages its own queue of incoming REST requests and serves them according to available capacity of current installation. This means that the application layer can request any number of queries and then just wait until they are processed.
Processing priority management - To allow off-queue high-priority or low-priority processing, SPE also allows the setting of priority for individual REST requests.
Basic audio manipulation - SPE has built-in basic audio file manipulation functionality, like separating individual channels from stereo recordings, cutting one audio to several files, saving audio from incoming stream to file and other functionalities.
Stream audio player - To support voicebot scenarios, SPE has the ability to play audiofiles directly to output RTP stream
External Text-to-speech (TTS) integration - Easy integration with external TTS providers via simple plugin-like connectors interface
Flexible integration - SPE can provide results in JSON or XML format. Results can be obtained by polling, via websockets, or via webhooks (callbacks).
Status information - SPE can provide various status information to the application layer, e.g. license status, configuration info, current overall load, pending operations status, …
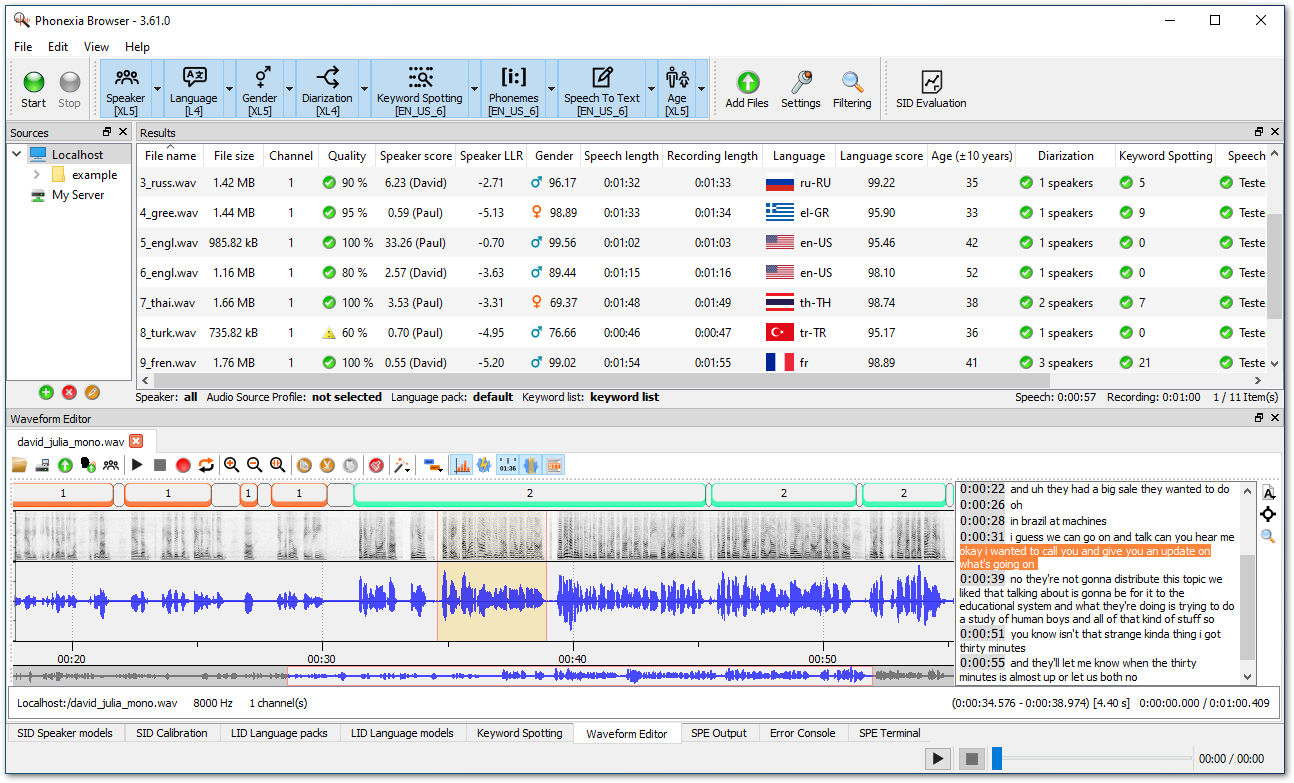
Phonexia Browser
Phonexia Browser is a testing tool, designed to easily evaluate speech technologies provided by Phonexia Speech Engine API without coding your own tools or scripts. It provides basic GUI for testing and visualizes the results of speech technologies using your own audio recordings.
Phonexia Browser helps with:
- becoming familiar with speech technologies
- deployment of Phonexia Speech Engine into the client’s infrastructure
- configuration of the technologies according to the client’s needs
- calibration and evaluation of the specific deployment