Voice Activity Detection
The Voice Activity Detection technology allows users to determine how much speech is present in a recording and display its exact occurrences. It provides graphical visualizations and precise timestamps for speech segments. Additionally, it enables users to listen to the recording while skipping non-speech events or periods of silence.
This page explains how to use Phonexia Voice Activity Detection in our web application. If you want to dive deeper into the inner workings of this technology, check out our detailed technical documentation.
Uploading files
Upload your files or create your own recordings by using the built-in recording feature. If you don't have your own files, you can use the provided Phonexia examples to explore how Voice Activity Detection works.
Read more about uploading files here.
Results
After uploading your recordings, they will appear in the left panel. Once processing is complete, the quick result—total speech length in the recording—is displayed on the right side of the left panel. More detailed results for each recording are shown in the right panel after clicking on a specific recording.
In the channel box, next to the channel number, you will find the speech length detected for the corresponding channel of the audio file. Below this, the speech segments are visualized as a blue waveform with a blue background highlight. By checking the box labeled "Play only speech segments," users can filter out all non-voice segments and listen exclusively to the speech.
The exact timestamps of a specific speech segment are displayed in a tooltip when hovering over it. Additionally, all speech segments are included in the export files described below.
Export formats
Once your results are ready, you can export them in various formats.
Voice Activity Detection results can be exported individually for each file in .CSV, .XLSX, or JSON format. Each export file is named after the corresponding audio file and includes key information such as the channel number, as well as the start and end times of each speech segment.
The same results can also be exported in bulk as a ZIP file. Additionally, users have the option to export a summary file that displays only the total speech length for each audio file.
XLSX format
The .XLSX format provides a clear, comprehensive, and human-readable overview of the metadata. In this format, timestamps are presented in the format: HH:MM:SS.
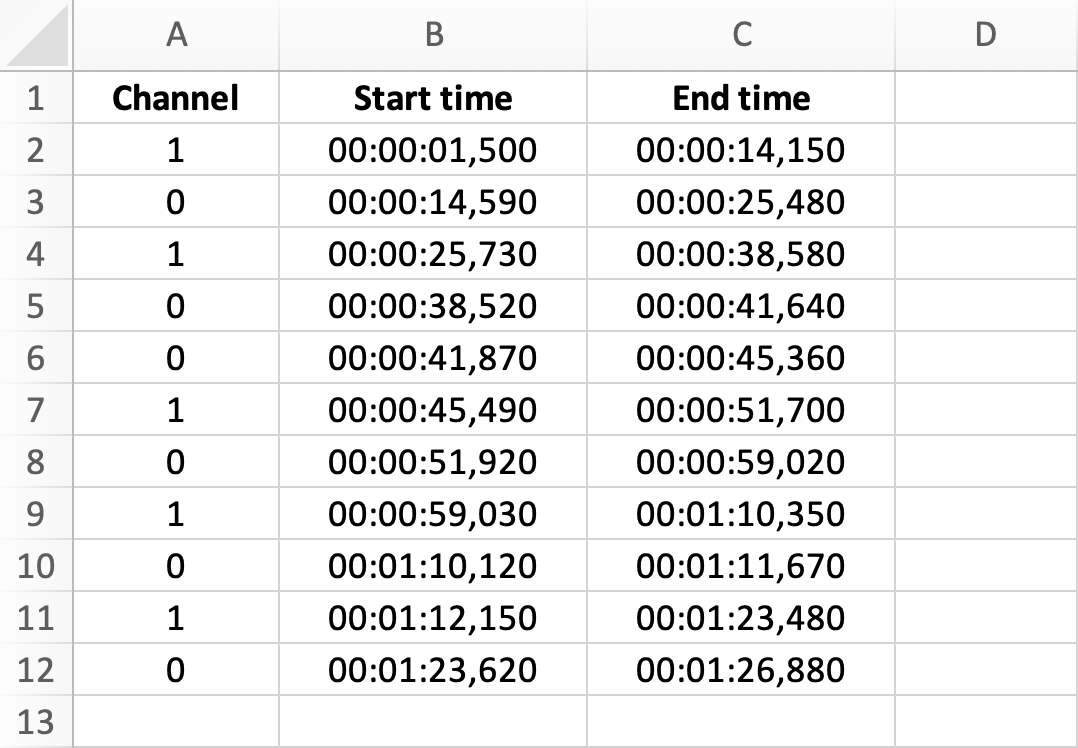
CSV format
The .CSV format contains the same information, however, start time and end time of each segment are expressed in seconds in this format. The .CSV format uses UTF-8 encoding.
Channel,Start time,End time
1,1.5,14.15
0,14.59,25.48
1,25.73,38.58
0,38.52,41.64
0,41.87,45.36
1,45.49,51.7
0,51.92,59.02
1,59.03,70.35
0,70.12,71.67
1,72.15,83.48
0,83.62,86.88
0,87.03,96.09
JSON format
Similar to the .CSV format, the JSON export format lists all voice-containing segments along with their timestamps for each channel.
{
"channels": [
{
"channel_number": 0,
"speech_length": 45.7,
"segments": [
{
"segment_type": "voice",
"start_time": 14.59,
"end_time": 25.48
},
{
"segment_type": "voice",
"start_time": 38.52,
"end_time": 41.64
}
]
},
{
"channel_number": 1,
"speech_length": 70.72,
"segments": [
{
"segment_type": "voice",
"start_time": 1.5,
"end_time": 14.15
},
{
"segment_type": "voice",
"start_time": 25.73,
"end_time": 38.58
},
{
"segment_type": "voice",
"start_time": 45.49,
"end_time": 51.7
}
]
}
]
}
All speech lengths
Whether in CSV or XLSX format, the export file displays the speech length for each selected recording.
Filename,Channel,Speech length
Barbara.wav,0,32.37
Harry.wav,0,38.76
Juan.wav,0,40.37
Kathryn_Paula.wav,0,45.7
Kathryn_Paula.wav,1,70.72
Laura_Marek.wav,0,21.71
Laura_Marek.wav,1,36.93
Obioma.wav,0,26.82
Veronika.wav,0,26.37