Performance
The Enhanced Speech to Text built on Whisper employs a large language model with millions of parameters, making it very resource-intensive. While we've implemented optimizations to alleviate this, it still requires specialized hardware for optimal performance.
While running on CPUs is feasible, it's notably slower and challenging to scale. For best results in production, we strongly advise utilizing GPUs.
Performance optimizations
We've enhanced the performance of our Speech to Text solution by making use of the following optimizations:
Silence removal
We've implemented pre-filtering using Voice Activity Detection (VAD) to eliminate silent portions from recordings. This ensures that the model processes only segments containing speech. While the effectiveness of this optimization depends heavily on the amount of speech in recordings, it typically accelerates processing by 20% to 30%.
Inference optimization techniques
We employ various techniques, including weight quantization, layer fusion, and batch reordering, to enhance inference of the Whisper model. These optimizations lead to faster processing speeds and reduced memory usage. As a result, our Speech to Text solution requires less than half the memory compared to the OpenAI's implementation and achieves transcription speeds up to four times faster. See Table 1 for a detailed comparison.
| Implementation | Precision | Processing time [s] | Max Video RAM [MB] | Max RAM [MB] |
|---|---|---|---|---|
| OpenAI | fp16 | 132 | 11047 | 4364 |
| Phonexia | fp16 | 37 | 4395 | 1401 |
Table 1: Comparison of OpenAI and Phonexia performance on a 596-second audio file. Measurements were conducted on an Amazon g5.xlarge instance with a NVIDIA A10G GPU and 4XAMD EPYC 7R32 CPUs (each with 2 CPU cores.)
Vertical Scaling
To enhance overall throughput we enable better utilization of single hardware node resources through vertical scaling. This involves processing multiple transcription tasks in parallel. However, this technique may introduce higher latencies and is not enabled by default. Configuration for specific use cases is required. Refer to the article on scaling for more details.
Beam Reduction
Below is a sample measurement for accuracy and speed measurements for various English datasets and Whisper models.
As it is visible from the results, while WER1 stays similar across all used models, FTRT value2 of model with Beam Reduction is very high, especially compared to regular Whisper models. This means that model with Beam Reduction is several times faster on the same hardware than regular Whisper models.
The measurement was performed with one instance of Enhanced Speech to Text Built on Whisper microservice running on an NVIDIA RTX 4000 SFF Ada Generation GPU with 15GB of RAM.
Accuracy measurement (Word Error Rate):
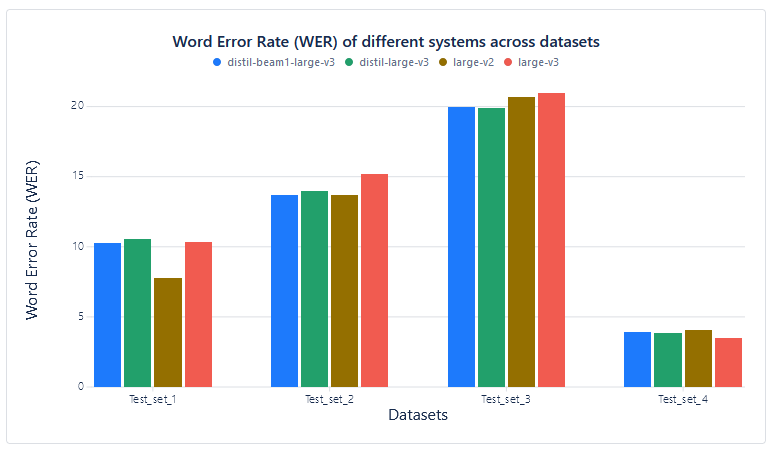
| Test set | distil-beam1-large-v3 | distil-large-v3 | large-v2 | large-v3 |
|---|---|---|---|---|
| Test_set_1 | 10.3 | 10.54 | 7.78 | 10.37 |
| Test_set_2 | 13.72 | 14 | 13.67 | 15.19 |
| Test_set_3 | 19.99 | 19.93 | 20.7 | 20.97 |
| Test_set_4 | 3.92 | 3.88 | 4.08 | 3.51 |
Speed measurement (Faster Than Real-Time):
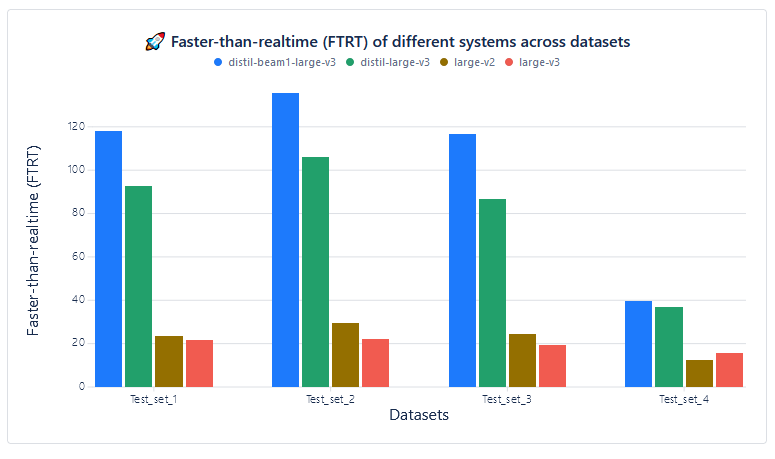
| Test set | distil-beam1-large-v3 | distil-large-v3 | large-v2 | large-v3 |
|---|---|---|---|---|
| Test_set_1 | 117.98 | 92.62 | 23.57 | 21.62 |
| Test_set_2 | 135.61 | 106.08 | 29.63 | 22.27 |
| Test_set_3 | 116.89 | 86.66 | 24.57 | 19.3 |
| Test_set_4 | 39.63 | 36.93 | 12.54 | 15.75 |
Beam-size parameter impact (large-v2 only):
Accuracy measurement (Word Error Rate):
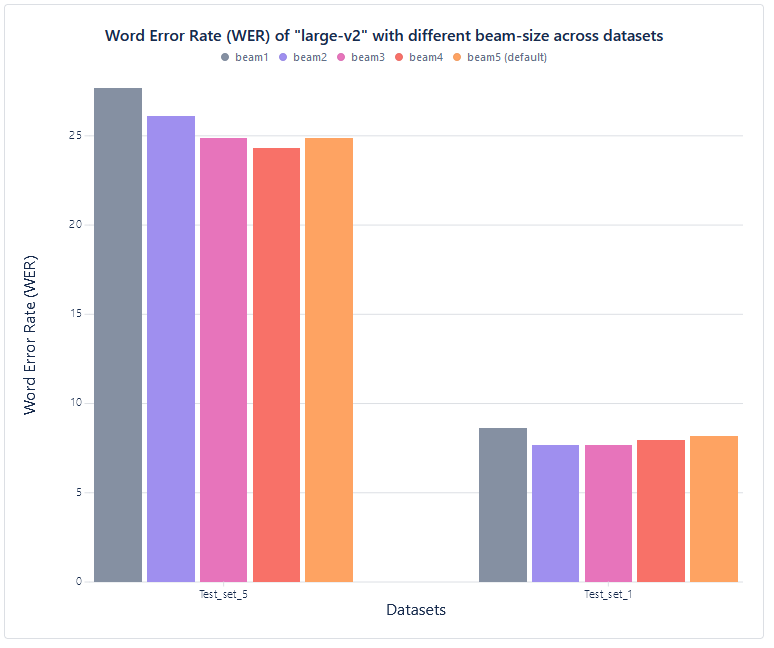
| Test set | beam1 | beam2 | beam3 | beam4 | beam5 (default) |
|---|---|---|---|---|---|
| Test_set_5 | 27.68 | 26.13 | 24.90 | 24.31 | 24.89 |
| Test_set_1 | 8.64 | 7.70 | 7.66 | 7.96 | 8.16 |
Speed measurement (Faster Than Real-Time):
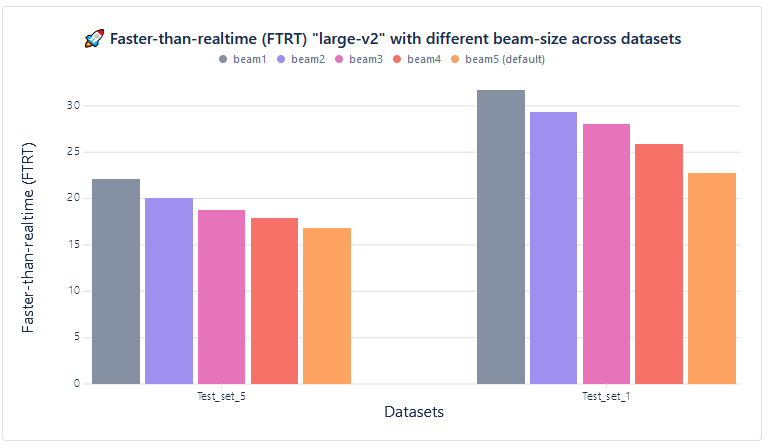
| Test set | beam1 | beam2 | beam3 | beam4 | beam5 (default) |
|---|---|---|---|---|---|
| Test_set_5 | 22.08 | 20.05 | 18.80 | 17.90 | 16.80 |
| Test_set_1 | 31.71 | 29.34 | 28.03 | 725.88 | 22.79 |
Language dependency
Large language models like Whisper operates by predicting sequences of tokens (sub-word units) from audio data. As research has shown, the number of tokens needed to represent a word or sentence can vary significantly depending on the language. This variation impacts processing time, as each token prediction requires substantial computational resources.
To understand the impact of language on processing time, we evaluated the performance across various languages. We focused on the actual speech duration within recordings, not the total audio length, thanks to the Voice Activity Detection (VAD) filtering incorporated in our Speech to Text solution. The speed of transcription is expressed as a Real-Time Factor (RTF), a metric calculated by dividing processing time by speech duration. It's important to note that other factors might also influence processing time, potentially affecting the results' precision.
Table 2 illustrates the differences in RTF across various languages. As expected, languages requiring fewer tokens per word tend to have faster processing speeds.
| Language | Total speech duration [s] | Processing time [s] | RTF [-] |
|---|---|---|---|
| English | 10276 | 612 | 16.79 |
| Portuguese | 9963 | 723 | 13.78 |
| Spanish | 9790 | 781 | 12.54 |
| Korean | 9592 | 812 | 11.81 |
| French | 8976 | 814 | 11.03 |
| Russian | 10554 | 970 | 10.88 |
| Japanese | 9113 | 844 | 10.8 |
| Slovak | 9029 | 873 | 10.34 |
| Polish | 8560 | 839 | 10.2 |
| Arabic | 9110 | 916 | 9.95 |
| Czech | 8820 | 991 | 8.9 |
Table 2: STT processing speed for various languages. Measurements were made on audio files from the Common Voice and Fleurs datasets. To simulate real-world scenarios with longer audio, we concatenated multiple short recordings from each dataset into recordings averaging 100 seconds in length. The measurements were conducted on an AMD Ryzen 9 7950X3D 16-Core Processor and a NVIDIA RTX 4000 SFF Ada Generation graphic card.
Footnotes
-
Word Error Rate - how accurate the model is. It is a percentage value that expresses how many words have been correctly transcribed with respect to a reference transcription. ↩
-
Faster Than Real-Time - indicates the speed-up factor of the processing relative to the audio duration - for example FTRT 10 means that 10 seconds of input audio is processed in 1 second of CPU time ↩