Overview
Integrated as part of the virtual appliance, Phonexia offers a distinctive web application designed for demonstrating the capabilities of Speech Platform 4 and catering to users who favor a simple, straightforward approach when working with small amounts of audio data.
Its clear and intuitive design guides users seamlessly through the speech technology features without confusion. It is responsive and adaptable to different screen sizes including mobile devices to maintain usability across various platforms. Furthermore, at Phonexia we conduct continuous usability testing with target users to gather feedback and insights on the effectiveness and user-friendliness of the web app design, iterating and refining the interface based on real-world usage scenarios of our technologies.
Current technologies
At the moment, Phonexia Speech Platform 4 offers 5 powerful technologies that can be used in the web app:
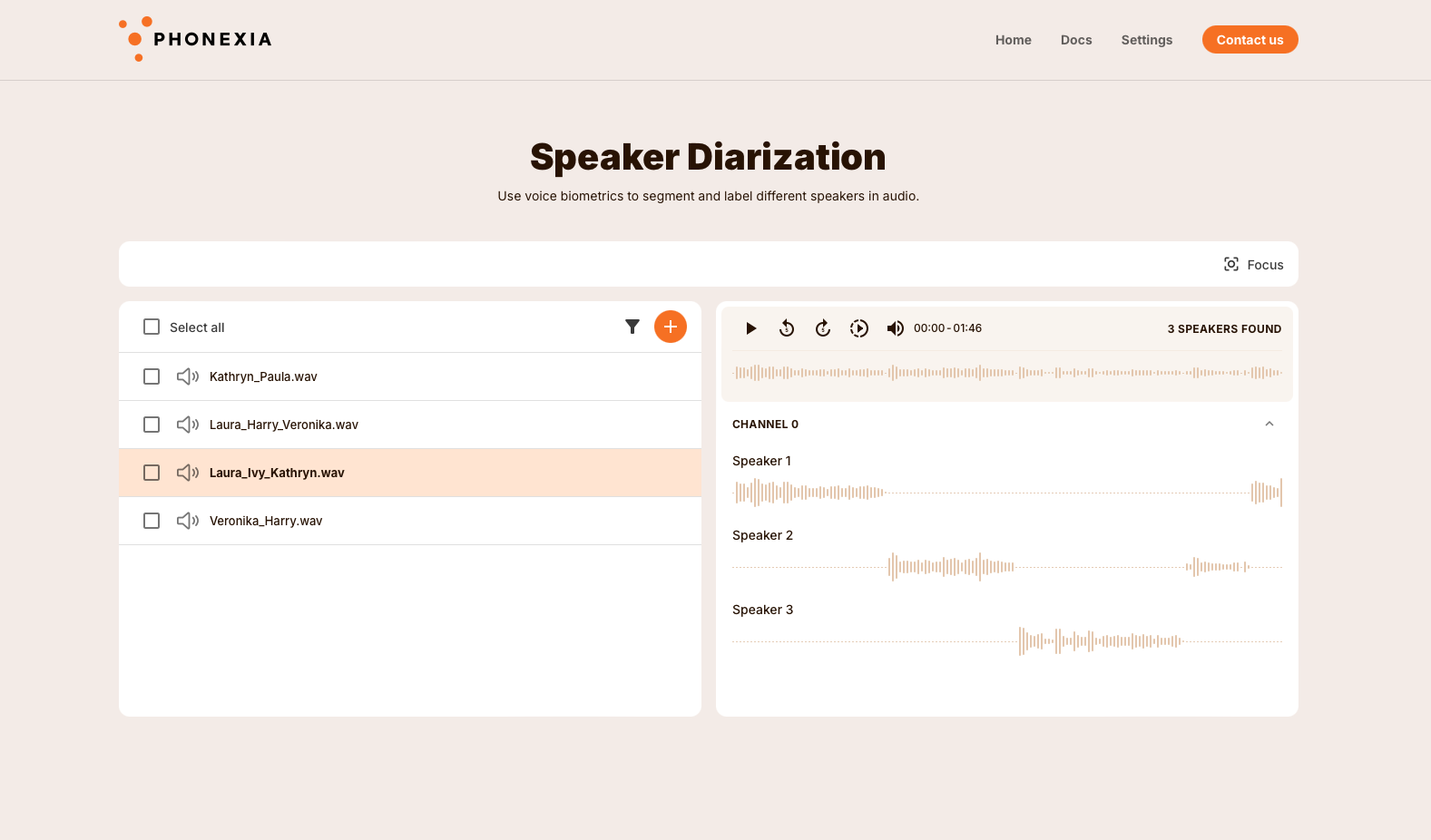
Speaker Identification
Phonexia Speaker Identification uses deep neural networks to create highly accurate mathematical models of the human voice (voiceprints) and provides rapid, highly accurate voice comparison for any scenario, from individual 1:1 voice verification to complex 1:N and N:M speaker identification.
The comparison of two recordings (or groups of recordings) occurs within two adjacent panes, where uploaded and processed audios are juxtaposed for comparison. Audios displaying a high similarity score (number in green) indicate a match with the voice in the selected recording in the neighboring pane.
You can learn more about Speaker Identification in our Technologies section.
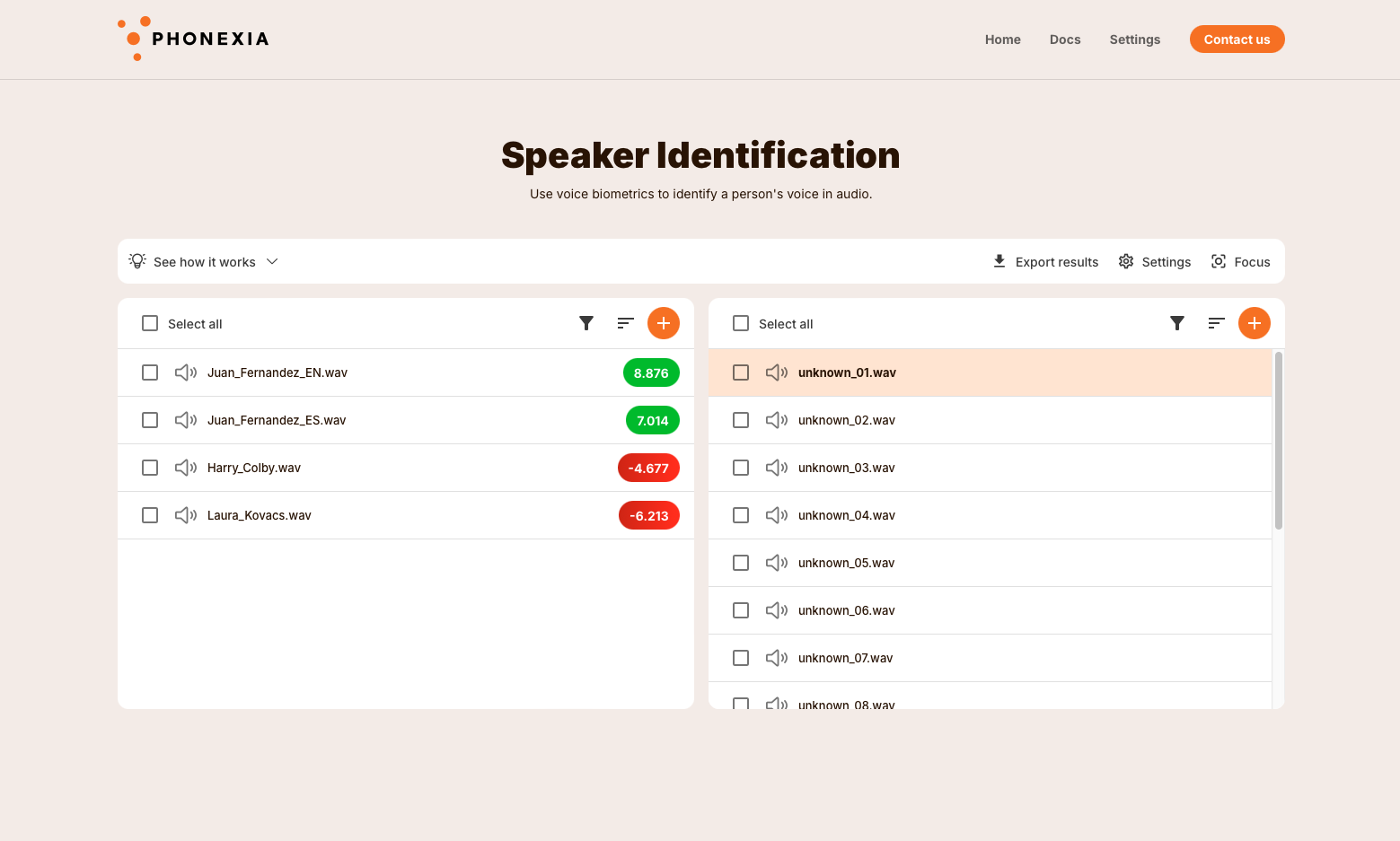
Speech to Text
Phonexia Speech to Text technology offers cutting-edge deep neural network models with large open-source models, providing an extensive transcription range of over 60 languages as well as automatic language detection. It incorporates state-ot-the-art channel compensation techniques, ensuring compatibility with a broad spectrum of audio sources, including GSM/CDMA, 3G, VoIP, landlines, and satellite phones.
In our web app, users are empowered to effortlessly upload media files featuring speech, with the option to specify their desired language or rely on automatic detection, streamlining the transcription process.
You can learn more about Phonexia 6th Gen Speech to Text and Enhanced Speech to Text Built on Whisper in our Technologies section.
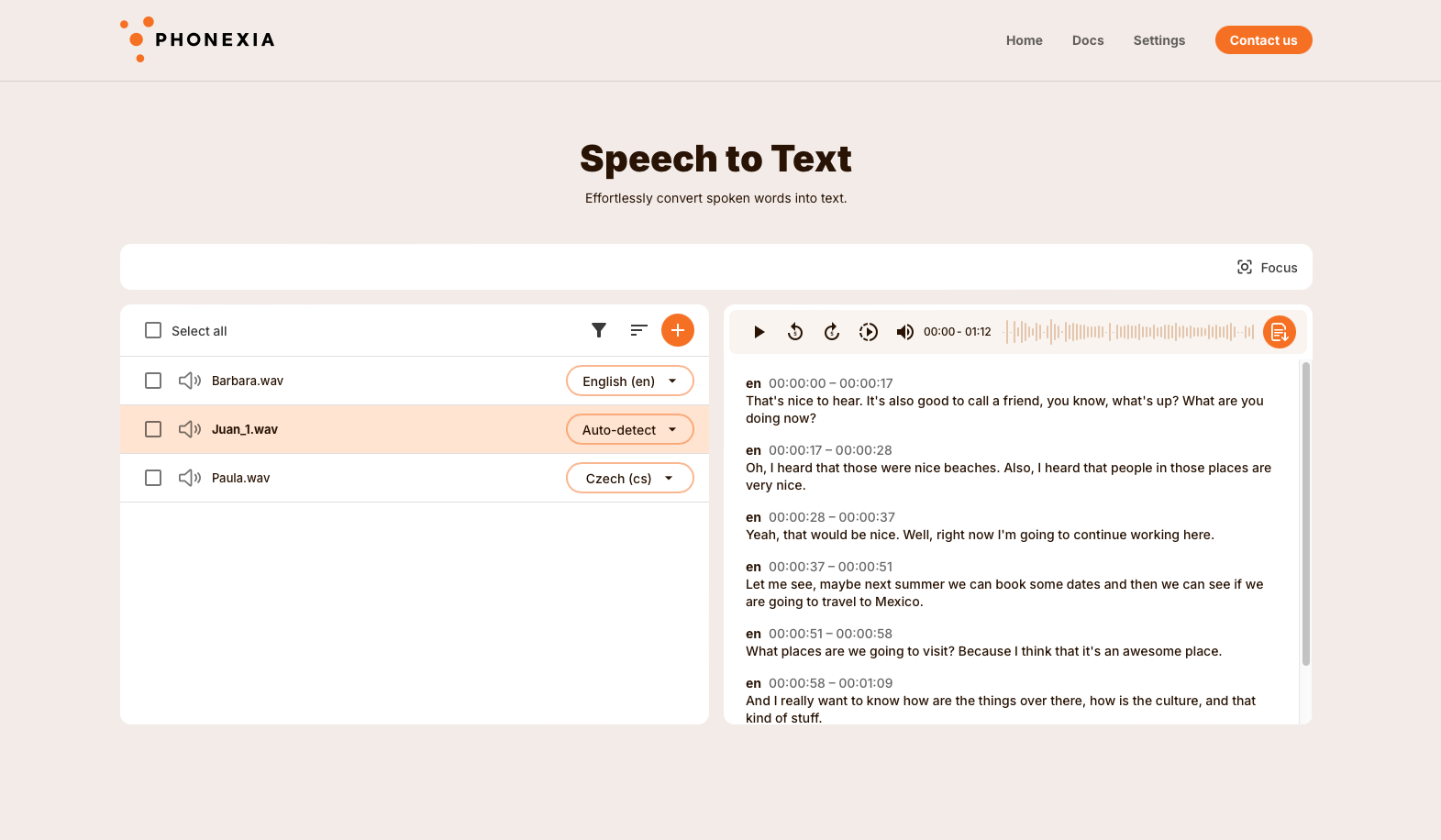
Language Identification
Phonexia Language Identification is an advanced tool designed to accurately detect the language spoken in an audio recording. This technology can distinguish between 140 languages from around the globe. Additionally, for widely spoken languages such as Spanish, Arabic, Chinese, and English, it can even identify regional varieties, offering a more granular level of language detection.
For each language detected in the recording, users can view a score represented as a percentage and a bar chart, both of which illustrate the likelihood of each language appearing in the audio.
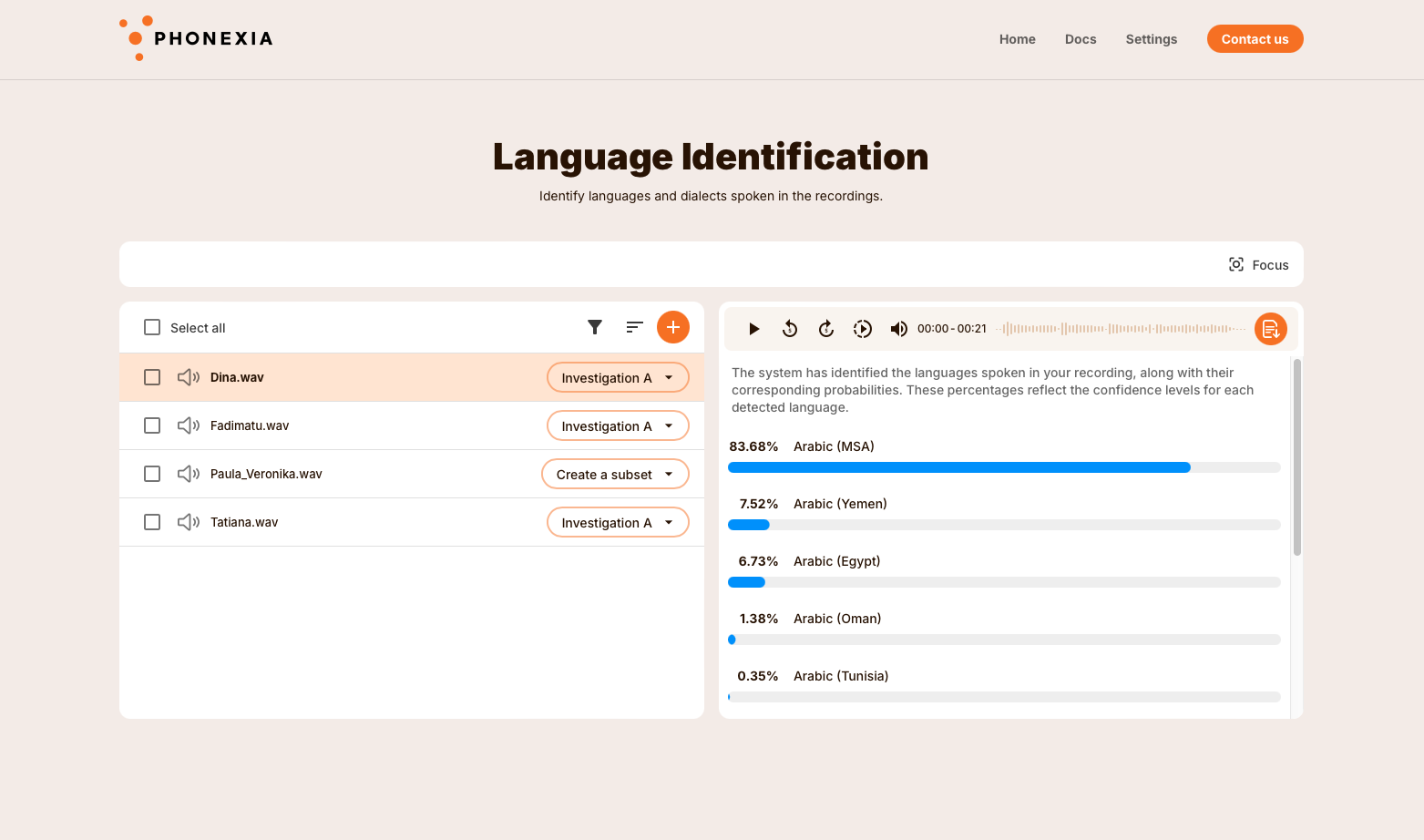
Diarization
Phonexia Diarization technology enables users to distinguish between multiple speakers present in a recording, whether it is mono or stereo, and also to identify the total number of speakers.
Our user-friendly web app further offers the possibility to listen to each speaker separately and export each speaker's audio as an individual file.
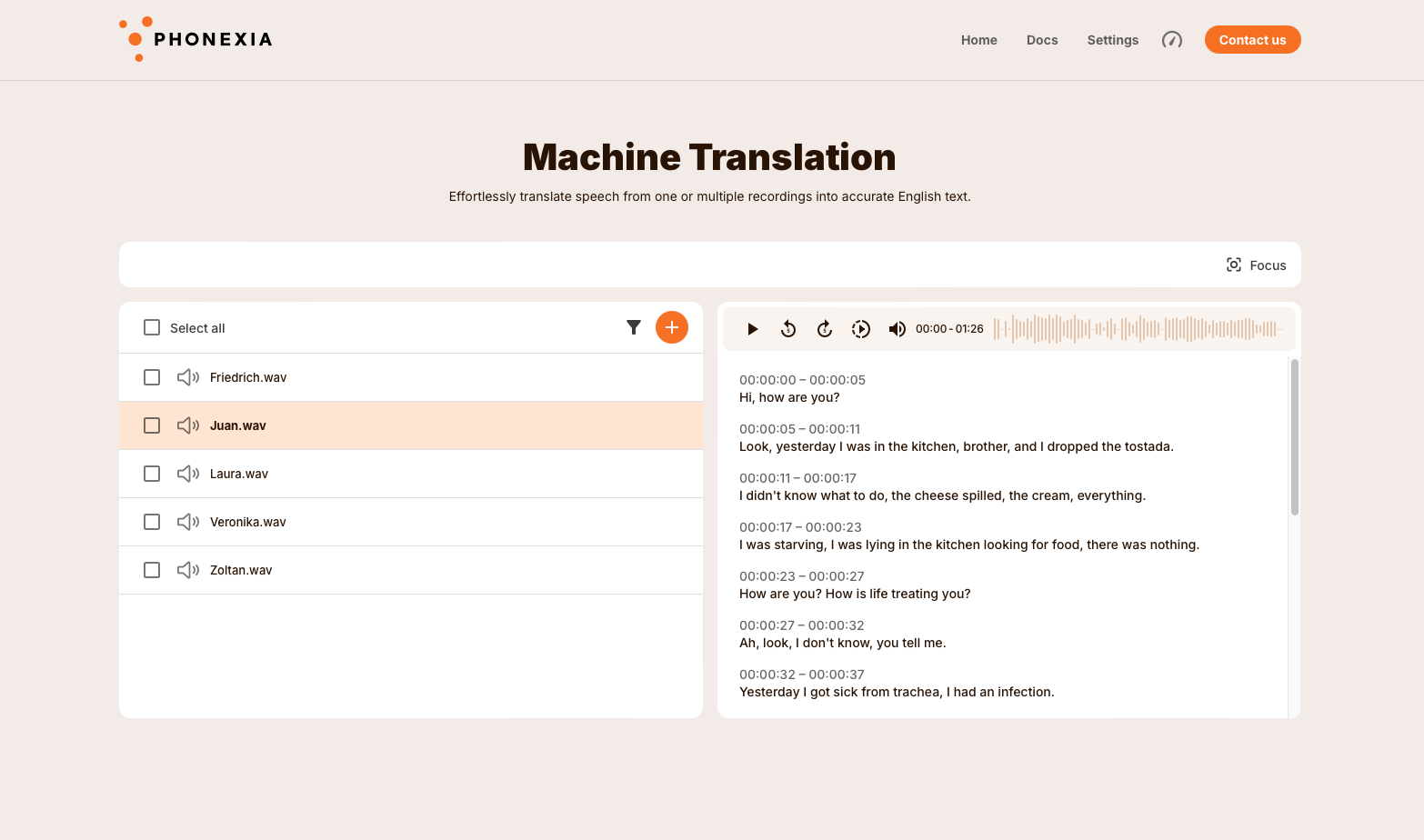
Machine Translation
The Phonexia Machine Translation tool enables users to effortlessly translate spoken language from audio files into precise English text.
Supporting over 60 languages, Phonexia delivers automatic translations immediately after users upload their files, ensuring a smooth and efficient process for managing multilingual speech data.
Similar to Phonexia Speech to Text, users can specify the language before processing, or the system will automatically detect it.
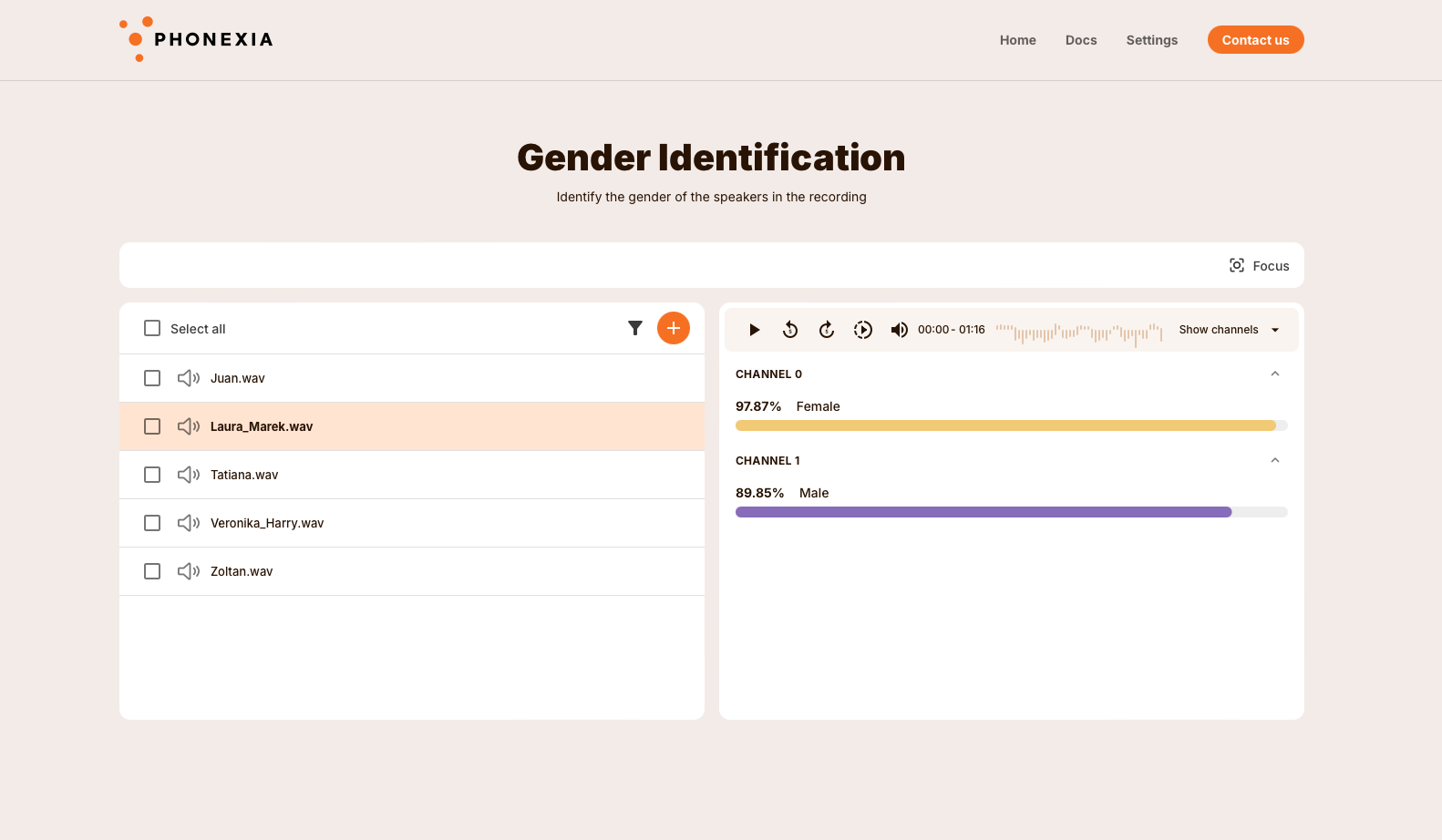
Gender Identification
Phonexia Gender Identification is a straightforward yet powerful tool designed to analyze speaker recordings and accurately determine the likelihood of male or female voice in the audio. This technology not only processes the recordings efficiently but also presents the results in a clear, visual format, allowing users to easily interpret the probabilities of each gender's presence within the audio file.
The probability score is represented as a percentage and illustrated with a bar chart that indicates the speaker's gender, using yellow for female and violet for male.
What's next to come?
At Phonexia we are continuously enhancing our Speech Platform 4 portfolio by integrating the latest innovations. Users can expect the introduction of the following technologies:
- Keyword Spotting
- Voice Activity Detection
- Speech Quality Estimation
- Authenticity Verification
- Denoiser
- Emotion Detection
- Age Estimation