Language Identification
Language Identification is a robust technology that enables users to detect the language spoken in an audio recording. It supports the identification of 140 languages from around the world and, for widely spoken languages, can even distinguish between regional varieties.
Have a look at the complete language portfolio of our Language Identification.
How it works
Creating a subset of languages
The first step is optional. By clicking "Select a subset," a new window will open where you can choose the languages or regions likely to be present in the recording. Excluding unlikely languages can help enhance the accuracy of the language identification results.
If you frequently work with a specific region and expect only a particular subset of languages to appear in your recordings, consider saving your language subset for repeated use. You can create and save as many custom subsets as needed.
Your language subsets are stored locally in your browser. If you switch devices or use a different browser, these subsets will no longer be available.
Uploading files
Afterwards, you can upload your files or create your own recordings by using the built-in recording feature. If you don't have your own files, you can use the provided Phonexia examples to explore how Language Identification works.
Read more about uploading files here.
Results
After uploading, your recordings will be listed in the left panel. Once processing is complete, the results for each recording will be displayed as a bar chart in the right panel. Only the languages detected with a significant score will be shown.
If you find that the identified language is incorrect after listening to the recordings, you can refine your results by creating a new subset. Click on the button next to the filename and create a subset or modify the current one by excluding the incorrect language from the list. This adjustment will help you obtain more accurate results.
Export formats
Once your results are ready, you can export them in various formats. Whether exporting multiple results at once or individually, you have the flexibility to choose from several export options. The .CSV format uses UTF-8 encoding.
Individual results
Language identification results can be exported for each file either individually or in bulk as a ZIP file. The available formats are .CSV and .XLSX. These files are named after the corresponding audio file and contain key information such as the channel, language, language code, and score (%), with the data sorted by score in descending order.
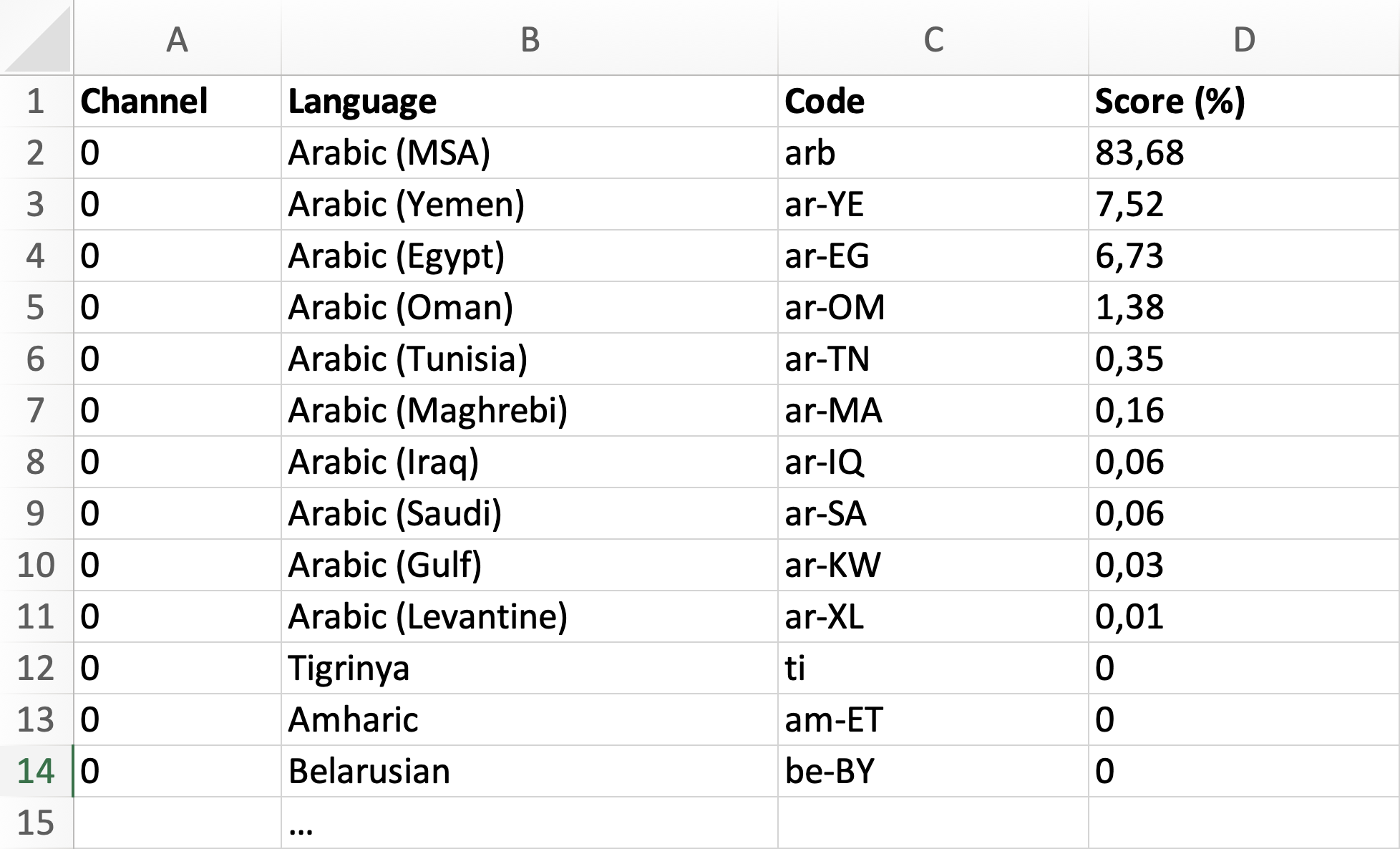
Best scores
The export file can be generated in both .XLSX and .CSV formats, displaying the top 5 highest-scoring languages for each recording. The table in both formats includes the following details: filename, channel, language code, and score for all five languages.

In the .CSV format, each line represents the filename, channel, and languages along with their respective scores, listed from highest to lowest, though this ordering is not explicitly labeled.
Filename,Channel,Code,Score (%),Code,Score (%),Code,Score (%),Code,Score (%),Code,Score (%)
Dina.wav,0,arb,83.68,ar-YE,7.52,ar-EG,6.73,ar-OM,1.38,ar-TN,0.35
Fadimatu.wav,0,ha,100,am-ET,0,ar-EG,0,ar-IQ,0,ar-KW,0
Paula_Veronika.wav,0,cs-CZ,99.98,sk-SK,0.02,am-ET,0,ar-EG,0,ar-IQ,0
Paula_Veronika.wav,1,cs-CZ,100,sk-SK,0,am-ET,0,ar-EG,0,ar-IQ,0
Tatiana.wav,0,ru-RU,99.51,be-BY,0.48,uk-UA,0.01,am-ET,0,ar-EG,0
All scores
This export is always in .CSV format and includes the scores for all languages supported by this technology for all the selected files.
Filename,Channel,ab-GE,af,am-ET,ar-EG,ar-IQ,ar-KW,ar-MA,ar-OM,ar-SA,ar-TN,ar-XL,ar-YE,arb,as-IN,ast-ES,az-AZ,ba-RU,be-BY,bg-BG,bn,bo,br-FR,ca-ES,ceb-PH,cs-CZ,cv-RU,cy-GB,da-DK,de,el-GR,en-AU,en-GB,en-IN,en-US,es-ES,es-XA,et-EE,eu,fa,fi-FI,fo,fr,ga-IE,gl-ES,gn,gu-IN,ha,haw-US,hbs,he-IL,hi-IN,ht-HT,hu-HU,hy-AM,id-ID,ig-NG,is-IS,it-IT,ja-JP,jv-ID,ka-GE,kam-KE,kea-CV,kk-KZ,km-KH,kn-IN,ko-KR,ku,ky-KG,lb-LU,lg-UG,ln,lo-LA,lt-LT,luo-KE,lv-LV,mg-MG,mi-NZ,min-CN,mk-MK,ml-IN,mn-MN,mr-IN,ms-MY,mt-MT,my-MM,nd-ZW,ne-NP,nl,no-NO,nr-ZA,ny-MW,oc-FR,om-ET,or-IN,pa,pl-PL,ps,pt,rn-BI,ro-RO,ru-RU,sd,si-LK,sk-SK,sl-SI,sn,so,sq-AL,ss-ZA,st-ZA,su-ID,sv-SE,sw,ta,te-IN,tg,th-TH,ti,tk,tl-PH,tn-ZA,tpi-PG,tr-TR,ts-ZA,tt,uk-UA,umb-AO,ur,uz-UZ,ve-ZA,vi-VN,wo,wuu-CN,xh-ZA,yi,yo,zh-CN,zh-HK,zu
Dina.wav,0,0,0,0,0.06731,0.00063,0.00033,0.00164,0.01381,0.00059,0.00352,0.00011,0.07521,0.83684,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.00001,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
Fadimatu.wav,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
Paula_Veronika.wav,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.99983,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.00017,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
Paula_Veronika.wav,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.99997,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.00003,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
Tatiana.wav,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.0048,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.99511,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.00009,0,0,0,0,0,0,0,0,0,0,0,0,0
If a language subset was applied during language identification processing, the result file for each recording and the "Best scores" format will reflect only the languages within that subset. Conversely, the "All Scores" format includes results for all 140 languages in the Phonexia Language Identification portfolio.