Speech to Text
Speech to text combines two powerful technologies, Phonexia 6th Gen and Whisper Enhanced, which support a wide range of languages. The number of visible language options is always tailored to the user's needs.
Have a look at the complete language portfolio of our Speech to Text.
How It Works
The first step is to select the language utilized in the recordings. If uncertain about the language, an alternative is to employ auto-detect mode, which seamlessly identifies the language and proceeds with transcription.
If you don't possess your own files, you can utilize Phonexia examples specifically configured for automatic transcription in auto-detect mode.
If you choose auto-detect, Speech to Text will only identify and use the languages from Whisper Enhanced portfolio.
The transcription process may take a while.
Pausing or deleting the recording while you await the transcription does not affect the transcription speed, as the transcription process continues uninterrupted on the server.
Leaving the page while awaiting transcription may result in process interruption.
Once your recordings are listed in the left pane, you can perform various operations with them:
- Downloading audio: Dowloads a zip file containing selected audio files.
- Deleting files: Deletes files from the browser.
- Exporting transcriptions: Downloads a zip file with selected transcriptions.
- Changing the language and transcription technology: Initiates the process of preparing a new transcription with the chosen language and transcription technology.
These actions can be carried out individually or in bulk for selected audio files. Furthermore, you can export the current transcription via the orange button located in the right pane next to the player.
Export formats
Whether you export as a bulk action or individually, you have the option to select from various export formats. All formats, with the exception of XLSX, utilize UTF-8 encoding.
Plain text
This format provides plain text without timestamps or any additional metadata. The text merges together the transcription of all speech without specifying individual channels.
Yeah, sure. Hold on a second. Where did I put it? Ah, here we are.
So the agreement number is 7895478. Right, the third digit. Where do I...
Oh, yes, it's nine. Oh, right, the security code. Sorry, not the agreement number.
Yeah, so the fourth and seventh digit you said, right? Fourth and seventh digit.
Okay, it's three and four. Well, I'm interested in the super speed tariff from your offer.
No, I think that's everything. Thank you.
Yeah, sounds good.
Yeah, that's all.
Cheers. You too.
Text with Timestamps
This format contains two types of data: timestamps and text. The text merges together the transcription of all speech without specifying individual channels.
00:00:01 Yeah, sure. Hold on a second. Where did I put it? Ah, here we are.
00:00:06 So the agreement number is 7895478. Right, the third digit. Where do I...
00:00:19 Oh, yes, it's nine. Oh, right, the security code. Sorry, not the agreement number.
00:00:26 Yeah, so the fourth and seventh digit you said, right? Fourth and seventh digit.
00:00:30 Okay, it's three and four. Well, I'm interested in the super speed tariff from your offer.
00:00:41 No, I think that's everything. Thank you.
00:00:45 Yeah, sounds good.
00:00:46 Yeah, that's all.
00:00:49 Cheers. You too.
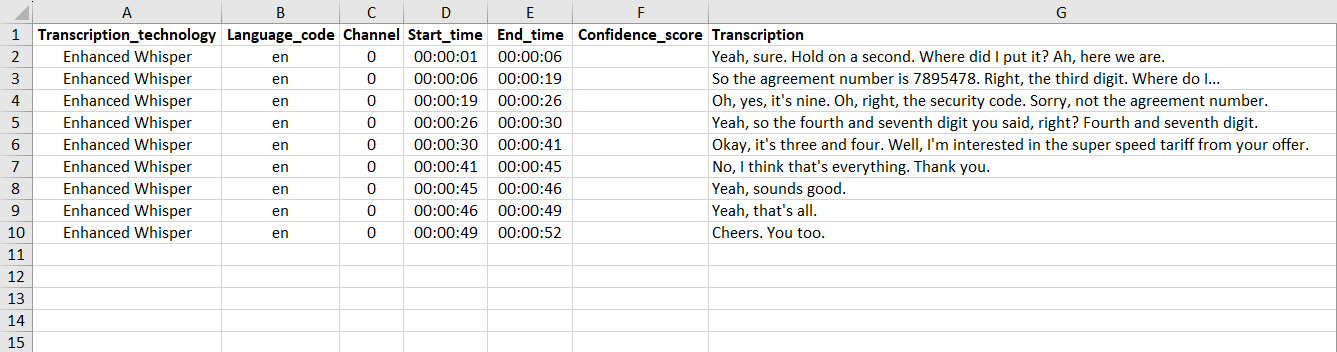
CSV and XLSX Format
These formats contain identical metadata: transcription technology, language of transcription, channel tags, segment timestamps, confidence score and the transcribed text.
The .CSV format is well-suited for users who work with large datasets, as it facilitates sophisticated computational processing and filtering based on specific metadata criteria. Start time and end time of each segment are represented as sums of seconds in this format.
Transcription_technology,Language_code,Channel,Start_time,End_time,Confidence_score,Transcription
Enhanced Whisper,en,0,1.06,6.8,,"Yeah, sure. Hold on a second. Where did I put it? Ah, here we are."
Enhanced Whisper,en,0,6.8,19.61,,"So the agreement number is 7895478. Right, the third digit. Where do I..."
Enhanced Whisper,en,0,19.61,26.01,,"Oh, yes, it's nine. Oh, right, the security code. Sorry, not the agreement number."
Enhanced Whisper,en,0,26.01,30.07,,"Yeah, so the fourth and seventh digit you said, right? Fourth and seventh digit."
Enhanced Whisper,en,0,30.07,41.58,,"Okay, it's three and four. Well, I'm interested in the super speed tariff from your offer."
Enhanced Whisper,en,0,41.58,45.6,,"No, I think that's everything. Thank you."
Enhanced Whisper,en,0,45.6,46.6,,"Yeah, sounds good."
Enhanced Whisper,en,0,46.6,49.46,,"Yeah, that's all."
Enhanced Whisper,en,0,49.46,52.49,,Cheers. You too.
The .XLSX format provides a clear, comprehensive, and human-readable overview of the metadata and textual content, catering to users who prefer working with more graphical data representation. In this format, timestamps are presented in the format: HH:MM:SS.
JSON Format
This format presents metadata similar to those mentioned above. Additionally, Phonexia 6th Gen provides segmentation per word. In other words, the JSON file of Phonexia transcription includes information about timestamps for each individual word.
- Whisper Enhanced
- Phonexia 6th GEN
{
"one_best": {
"segments": [
{
"channel_number": 0,
"end_time": 7.36,
"language": "en",
"start_time": 0.11,
"text": "how are you? yeah i'm fine also no it's okay actually i'm calling because i really like talking to you so"
},
{
"channel_number": 0,
"end_time": 16.45,
"language": "en",
"start_time": 7.36,
"text": "just throw it away yeah i get it it can be weird like we're very different people we think very"
},
{
"channel_number": 0,
"end_time": 26.88,
"language": "en",
"start_time": 16.45,
"text": "differently so it's but i think it's fun i'm here for you so yeah of course it helps you like"
}
]
}
}
{
"one_best": {
"segments": [
{
"channel_number": 0,
"end_time": 0.987,
"start_time": 0.271,
"text": "how are you",
"words": [
{
"end_time": 0.42,
"start_time": 0.271,
"text": "how"
},
{
"end_time": 0.571,
"start_time": 0.42,
"text": "are"
},
{
"end_time": 0.987,
"start_time": 0.571,
"text": "you"
}
]
},
{
"channel_number": 0,
"end_time": 7.80,
"start_time": 1.89,
"text": "yeah <silence/> i'm fine also <silence/> no <silence/> that's okay",
"words": [
{
"end_time": 2.28,
"start_time": 1.89,
"text": "yeah"
},
{
"end_time": 2.31,
"start_time": 2.28,
"text": "<silence/>"
},
{
"end_time": 2.37,
"start_time": 2.31,
"text": "i'm"
},
{
"end_time": 2.76,
"start_time": 2.37,
"text": "fine"
},
{
"end_time": 3.3,
"start_time": 2.76,
"text": "also"
},
{
"end_time": 3.895,
"start_time": 3.3,
"text": "<silence/>"
},
{
"end_time": 4.253,
"start_time": 3.895,
"text": "no"
},
{
"end_time": 4.282,
"start_time": 4.253,
"text": "<silence/>"
},
{
"end_time": 4.44,
"start_time": 4.282,
"text": "that's"
},
{
"end_time": 4.83,
"start_time": 4.44,
"text": "okay"
}
]
}
]
}
}