Waveform Denoiser
Phonexia Waveform Denoiser (DENOISER) provides automatic dereverberation (removal of echoes caused by sound reflections in rooms) and noise reduction of the speech signal. The data model is typically trained on various types of noise using the latest generation of neural network-based algorithms. The software primarily removes noises similar to those it was trained on. However, it cannot remove unwanted speech or music in the background.
The Denoiser is used to reduce noise in recordings while simultaneously amplifying the speech signal to:
- Improve intelligibility for human listeners (recommended use).
- Enhance the performance of automatic speech recognition technologies (testing on customer data is necessary first).
Input
- Audio file (for format details, see the Speech Engine documentation); streaming is not supported.
- Technology model name to be used for processing.
Output
-
Processed audio file (WAV or RAW format), along with an XML/JSON report (available in SPE only).
-
Audio file (for format details, see the Speech Engine documentation); streaming is not supported.
-
Technology model name to be used for processing.
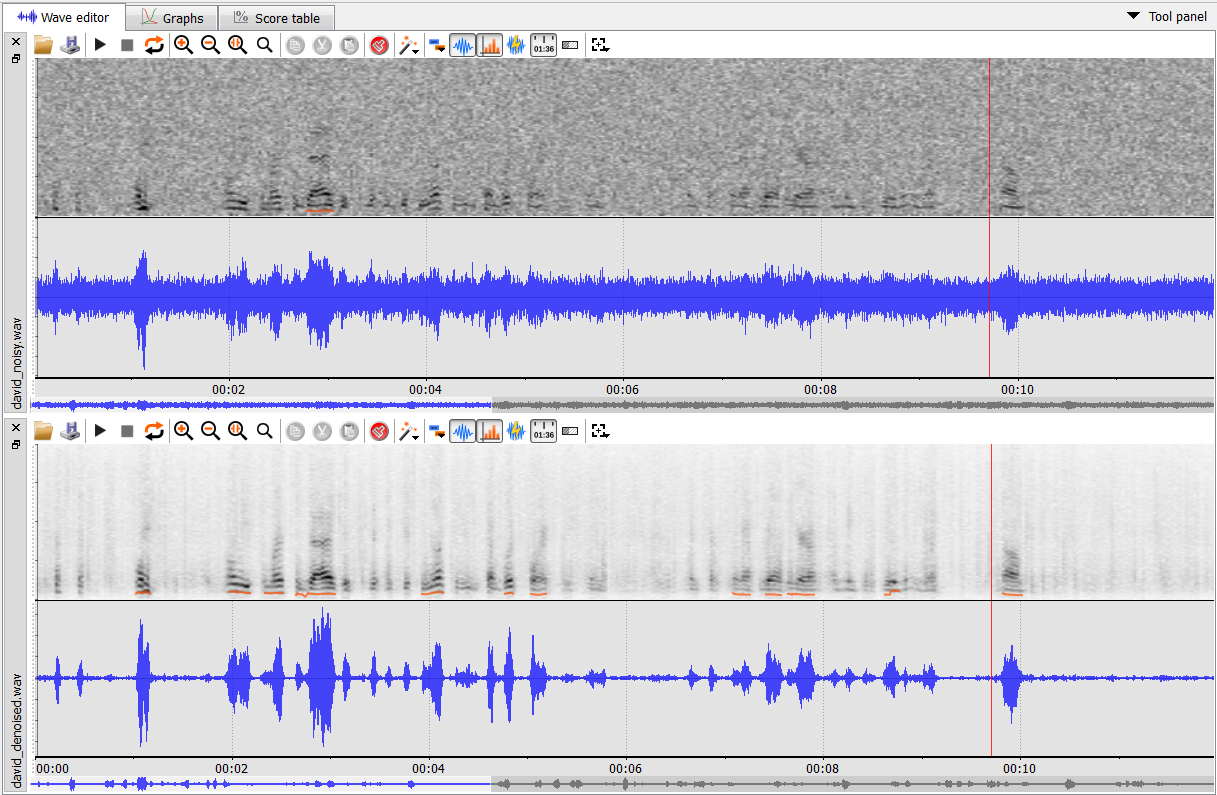
Figure 1.: Comparison of original recording (david_noisy.wav, top half of image) and same recording processed by Denoiser (david_denoised.wav, bottom half of the image).
Typical questions
Q: What do you recommend for deploying this technology?
It is advisable to use the technology after performing an acoustic quality check of the recordings. If technical information, such as a low signal-to-noise ratio (SNR), is detected, it is recommended to direct the recording to the Denoiser for automatic noise reduction. However, it is not advisable to send an automatically reconstructed recording to Speech to Text (STT) or Speaker Identification (SID) technologies afterward.
Q: How does the Denoiser perform if part of the recording is noisy and part of the speech is of good quality?
The technology is designed to automatically detect low-quality audio segments and attempt to reconstruct them. Conversely, well-recorded segments should be recognized and preserved in their original quality.
Q: Is there a way to adapt this technology?
No, unfortunately, the software does not currently offer easy customization options.