Results Explained
This article provides detailed information about Speech to Text outputs and offers guidance on tailoring Speech to Text technology to best meet your needs.
During the transcription process, the Speech to Text technology typically identifies multiple alternatives for individual speech segments. This occurs because multiple phrases can have similar pronunciations, possibly with different word boundaries, such as “eight tea machines” versus “eighty machines.”
The technology offers various output types that display either single or multiple transcription alternatives. For real-time stream processing, two result modes are supported: one mode delivers complete transcription, while the second mode provides incremental results.
Output types
- One-best output: Provides a transcription containing only the highest-scoring words.
- N-best output: Offers multiple alternatives for entire sentences or longer sequences of words.
- Confusion network output: Similar to N-best output, but returns multiple alternatives for individual words.
One-best output
{
"channel_id": 0,
"score": -0.04235574,
"confidence": 0.95852876,
"start": 3600000,
"end": 4190000,
"word": "you"
}
Start and end time are provided in HTK units. One HTK unit is equal to 100 nanoseconds. To convert these values to milliseconds, divide by 10,000.
Score represents a logarithm of probability within the range of (-∞, 0]. A higher score indicates a greater likelihood that the word was spoken during the specified time frame.
Confidence is a probability value within the range [0, 1]. It is derived
from the score using the formula e^(score). To express confidence as a
percentage, multiply the value by 100.
Some older legacy models do not support confidence scoring. These models can be identified by a confidence value of -1 at the recording level.
"one_best_result": {
"confidence": -1,
"segmentation": [
...
]
}
N-best output
{
"phrase": "can you hear me okay i wanted to",
"channel": 0,
"score": 509.71384,
"confidence": 0.3373934,
"start": 1500000,
"end": 28200000
}
This format can be utilized by analytical applications to further process transcription alternatives. It is also beneficial when a speaker does not pronounce a word correctly, and the one-best results do not match what the speaker actually said.
Start and end time are given in HTK units. One HTK unit equals 100 nanoseconds. To convert these values to milliseconds, divide by 10,000.
Score is a measure of how well the phrase matches the acoustic and language model, with values ranging from (-∞, +∞).
Confidence is a normalized probability within the range [0, 1]. Multiplying this value by 100 converts it to a percentage, representing the confidence level.
Confusion Network Output
{
"time_slot": 1,
"start_time": 1500000,
"end_time": 3600000,
"word": "I",
"posterior_probability": 0.986744345985676,
"channel": 0
}
Confusion networks can be used for further processing in a manner similar to n-best output.
- Time Slot: A designated period for which alternatives are determined.
- Start Time and End Time: Represented in HTK units, where 1 HTK unit equals 100 nanoseconds. To convert these values to milliseconds, divide by 10,000.
- Posterior Probability: A normalized probability value in the range of
{0,1}for a word within the specified time slot. Multiplying this value by 100 yields the percentage probability. The sum of all probabilities within a given time slot equals 1. The word with the highest probability within that time slot is included in the one-best output (see also How to Properly Convert Confusion Network Results to One-Best article).
- Start and end times of alternatives within a single time slot correspond precisely to the given alternative.
- In legacy versions, all alternatives within a single time slot had uniform start and end times common to the entire time slot.
- Current
- Legacy (up to 3.23)
[
{
"time_slot": 11,
"start_time": 17700000,
"end_time": 21850000,
"word": "tom",
"posterior_probability": 0.3793025,
"channel": 0
},
{
"time_slot": 11,
"start_time": 17650000,
"end_time": 21850000,
"word": "pong",
"posterior_probability": 0.1612993,
"channel": 0
},
{
"time_slot": 11,
"start_time": 17650000,
"end_time": 21850000,
"word": "tong",
"posterior_probability": 0.1344358,
"channel": 0
},
{
"time_slot": 11,
"start_time": 17650000,
"end_time": 21850000,
"word": "talk",
"posterior_probability": 0.0215998,
"channel": 0
},
{
"time_slot": 11,
"start_time": 17650000,
"end_time": 18110000,
"word": "<silence>",
"posterior_probability": 0.3033622,
"channel": 0
}
]
[
{
"time_slot": 10,
"start_time": 17650000,
"end_time": 18850000,
"word": "<silence>",
"posterior_probability": 0.3917705,
"channel": 0
},
{
"time_slot": 10,
"start_time": 17650000,
"end_time": 18850000,
"word": "tom",
"posterior_probability": 0.2152909,
"channel": 0
},
{
"time_slot": 10,
"start_time": 17650000,
"end_time": 18850000,
"word": "pong",
"posterior_probability": 0.1557797,
"channel": 0
},
{
"time_slot": 10,
"start_time": 17650000,
"end_time": 18850000,
"word": "tong",
"posterior_probability: 0.1334270,
"channel": 0
},
{
"time_slot": 10,
"start_time": 17650000,
"end_time": 18850000,
"word": "<null>",
"posterior_probability": 0.0755286,
"channel": 0
},
{
"time_slot": 10,
"start_time": 17650000,
"end_time": 18850000,
"word": "talk",
"posterior_probability": 0.0282029,
"channel": 0
}
]
Special tokens in outputs
The outputs can contain the following special tokens:
| Token (5th STT generation and newer) | Token (legacy STT generations) | Meaning |
|---|---|---|
<segment> | <s> | start of utterance |
</segment> | </s> | end of utterance |
<silence/> | _SILENCE_ or <sil/> | silent part (or no speech detected) |
<null/> | _DELETE_ | time slot should not go to one-best output |
Realtime stream processing output modes
Only single-channel (mono) audio is supported in realtime streams.
Complete mode
This is the default mode selected for returning transcription of realtime
stream, if no other mode is explicitly selected when
starting the transcription,
or when the result_mode=complete parameter is used.
In this mode, each
request for transcription results
returns the complete transcription since the beginning.
Incremental mode
This mode is used if the
transcription is started
using result_mode=incremental parameter in the request.
In this mode, each
request for transcription results
returns only changes since the last request for results.
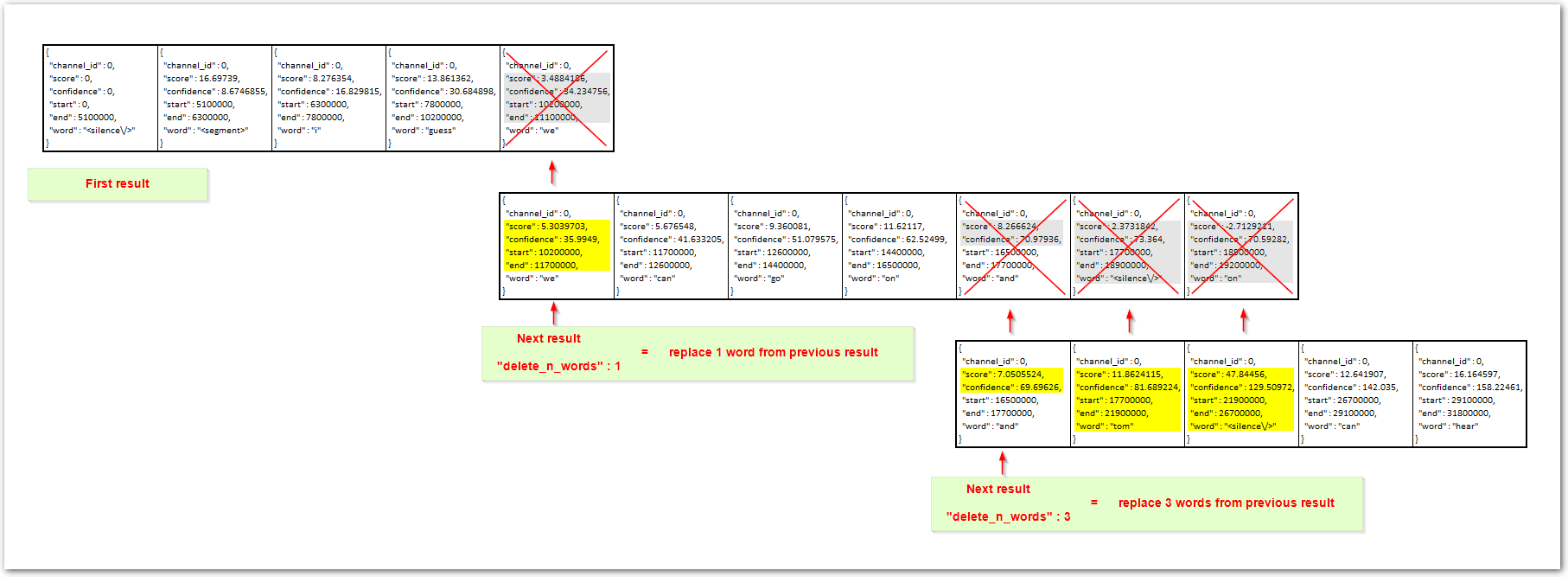
In incremental mode, the results received may update or correct previous results. For example, if a request is sent in the middle of a word, the next request may provide a correction by including the full word. When saying the word "happiness," the first result might show "happy," and the following result would update it to "happiness." This correction would also involve changes to the "start" and "end" times, as well as adjustments to the "score" and "confidence" values.
These corrections are indicated by a delete_n_words value in the results,
which specifies how many previously received words should be removed and
replaced with the new ones.
Hint:
These corrections never go back beyond the end-of-segment boundary
(</segment> token). In other words, they may happen only within a single
segment boundary.
Realtime stream processing output
Historically, realtime stream processing provided only a single output type –
one-best.
The one-best results are updated continuously, i.e., as soon as a new speech
element is recognized, it's immediately available in the output.
To enhance support for voicebot applications, the following additions have been implemented:
sentence_infoarray: This array includes aconfidencevalue for each sentence in the one-best results (available since version 3.24).
(A sentence is defined as the content between a<segment>and</segment>token. Therefore, if there are two such sentences in the results, thesentence_infoarray will contain two elements.)n_best_resultobject: This object provides additional n-best output (available since version 3.30).
The n-best results are updated after each segment/sentence, i.e., they are
only available in the output when the end-of-segment boundary (</segment>
token) is encountered in the one-best output.
Examples
Examples of new generation and legacy file processing Speech To Text outputs:
Examples
- One-best
- N-best
- Confusion Network
- One-best (legacy)
- N-best (legacy)
- Confusion Network (legacy)
...
{
"channel_id" : 0,
"score" : 0,
"confidence" : 0,
"start" : 0,
"end" : 1750000,
"word" : "<silence\/>"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 1750000,
"end" : 6250000,
"word" : "<segment>"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 6250000,
"end" : 8050000,
"word" : "i"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 8050000,
"end" : 10450000,
"word" : "guess"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 10450000,
"end" : 11950000,
"word" : "we"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 11950000,
"end" : 12850000,
"word" : "can"
},
{
"channel_id" : 0,
"score" : -0.07130883,
"confidence" : 0.9311743,
"start" : 12850000,
"end" : 14350000,
"word" : "go"
},
{
"channel_id" : 0,
"score" : -0.07130883,
"confidence" : 0.9311743,
"start" : 14350000,
"end" : 16450000,
"word" : "on"
},
{
"channel_id" : 0,
"score" : -0.096377626,
"confidence" : 0.908121,
"start" : 16450000,
"end" : 17700000,
"word" : "and"
},
{
"channel_id" : 0,
"score" : -0.9694211,
"confidence" : 0.37930256,
"start" : 17700000,
"end" : 21850000,
"word" : "tom"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 21850000,
"end" : 26650000,
"word" : "<silence\/>"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 26650000,
"end" : 29050000,
"word" : "can"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 29050000,
"end" : 31750000,
"word" : "hear"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 31750000,
"end" : 33550000,
"word" : "me"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 33550000,
"end" : 39850000,
"word" : "<silence\/>"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 39850000,
"end" : 46450000,
"word" : "okay"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 46450000,
"end" : 47350000,
"word" : "<silence\/>"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 47350000,
"end" : 49450000,
"word" : "i"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 49450000,
"end" : 52750000,
"word" : "wanted"
},
{
"channel_id" : 0,
"score" : -0.06587691,
"confidence" : 0.9362461,
"start" : 52750000,
"end" : 53650000,
"word" : "to"
},
{
"channel_id" : 0,
"score" : -0.026506705,
"confidence" : 0.97384155,
"start" : 53650000,
"end" : 57240000,
"word" : "call"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 57240000,
"end" : 58750000,
"word" : "you"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 58750000,
"end" : 59950000,
"word" : "and"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 59950000,
"end" : 62350000,
"word" : "give"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 62350000,
"end" : 63250000,
"word" : "you"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 63250000,
"end" : 64450000,
"word" : "an"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 64450000,
"end" : 68050000,
"word" : "update"
},
{
"channel_id" : 0,
"score" : -1.0996883,
"confidence" : 0.33297482,
"start" : 68050000,
"end" : 70050000,
"word" : "now"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 70050000,
"end" : 72850000,
"word" : "was"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 72850000,
"end" : 76750000,
"word" : "going"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 76750000,
"end" : 80440000,
"word" : "on"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 80440000,
"end" : 80440000,
"word" : "<\/segment>"
},
...
...
"variant" : [
{
"phrase" : "i guess we can go on and tom can hear me okay i wanted to call you and give you an update now was going on",
"channel" : 0,
"score" : 1193.6251,
"confidence" : 0.20036009
},
{
"phrase" : "i guess we can go on and pong can hear me okay i wanted to call you and give you an update now was going on",
"channel" : 0,
"score" : 1192.7487,
"confidence" : 0.20000915
},
{
"phrase" : "i guess we can go on and kong can hear me okay i wanted to call you and give you an update now was going on",
"channel" : 0,
"score" : 1192.6539,
"confidence" : 0.19997129
},
{
"phrase" : "i guess we can go on and tong can hear me okay i wanted to call you and give you an update now was going on",
"channel" : 0,
"score" : 1192.3292,
"confidence" : 0.19984145
},
{
"phrase" : "i guess we can go on and tom can hear me okay i wanted to call you and give you an update i'll was going on",
"channel" : 0,
"score" : 1192.2706,
"confidence" : 0.19981802
}
]
...
...
{
"time_slot" : 0,
"start_time" : 0,
"end_time" : 1750000,
"word" : "_SILENCE_",
"posterior_probability" : 0,
"channel" : 0
},
{
"time_slot" : 1,
"start_time" : 1750000,
"end_time" : 6250000,
"word" : "<segment>",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 2,
"start_time" : 6250000,
"end_time" : 8050000,
"word" : "i",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 3,
"start_time" : 8050000,
"end_time" : 10440000,
"word" : "guess",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 4,
"start_time" : 10150000,
"end_time" : 10450000,
"word" : "<silence\/>",
"posterior_probability" : 0.012546446098033464,
"channel" : 0
},
{
"time_slot" : 4,
"start_time" : 0,
"end_time" : 0,
"word" : "<null\/>",
"posterior_probability" : 0.987453555866488,
"channel" : 0
},
{
"time_slot" : 5,
"start_time" : 10450000,
"end_time" : 11950000,
"word" : "we",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 6,
"start_time" : 11950000,
"end_time" : 12850000,
"word" : "can",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 7,
"start_time" : 12850000,
"end_time" : 14350000,
"word" : "go",
"posterior_probability" : 0.9311742741997164,
"channel" : 0
},
{
"time_slot" : 7,
"start_time" : 0,
"end_time" : 0,
"word" : "<null\/>",
"posterior_probability" : 0.06882572183050334,
"channel" : 0
},
{
"time_slot" : 8,
"start_time" : 12850000,
"end_time" : 16450000,
"word" : "gone",
"posterior_probability" : 0.06882572183050334,
"channel" : 0
},
{
"time_slot" : 8,
"start_time" : 14350000,
"end_time" : 16450000,
"word" : "on",
"posterior_probability" : 0.9311742741997164,
"channel" : 0
},
{
"time_slot" : 9,
"start_time" : 16450000,
"end_time" : 17650000,
"word" : "and",
"posterior_probability" : 0.9081210211463454,
"channel" : 0
},
{
"time_slot" : 9,
"start_time" : 16450000,
"end_time" : 17650000,
"word" : "in",
"posterior_probability" : 0.09187897227139633,
"channel" : 0
},
{
"time_slot" : 10,
"start_time" : 17650000,
"end_time" : 17950000,
"word" : "<silence\/>",
"posterior_probability" : 0.07445526308627319,
"channel" : 0
},
{
"time_slot" : 10,
"start_time" : 0,
"end_time" : 0,
"word" : "<null\/>",
"posterior_probability" : 0.9255447284442746,
"channel" : 0
},
{
"time_slot" : 11,
"start_time" : 17700000,
"end_time" : 21850000,
"word" : "tom",
"posterior_probability" : 0.3793025570943731,
"channel" : 0
},
{
"time_slot" : 11,
"start_time" : 17650000,
"end_time" : 21850000,
"word" : "pong",
"posterior_probability" : 0.16129939404151145,
"channel" : 0
},
{
"time_slot" : 11,
"start_time" : 17650000,
"end_time" : 21850000,
"word" : "tong",
"posterior_probability" : 0.1344358893882311,
"channel" : 0
},
{
"time_slot" : 11,
"start_time" : 17650000,
"end_time" : 21850000,
"word" : "talk",
"posterior_probability" : 0.021599880199974865,
"channel" : 0
},
{
"time_slot" : 11,
"start_time" : 17650000,
"end_time" : 18110000,
"word" : "<silence\/>",
"posterior_probability" : 0.3033622683999196,
"channel" : 0
},
{
"time_slot" : 12,
"start_time" : 18850000,
"end_time" : 21850000,
"word" : "on",
"posterior_probability" : 0.056687105983052107,
"channel" : 0
},
{
"time_slot" : 12,
"start_time" : 17950000,
"end_time" : 21850000,
"word" : "kong",
"posterior_probability" : 0.2466751479018553,
"channel" : 0
},
{
"time_slot" : 12,
"start_time" : 0,
"end_time" : 0,
"word" : "<null\/>",
"posterior_probability" : 0.6966377414561294,
"channel" : 0
},
{
"time_slot" : 13,
"start_time" : 21850000,
"end_time" : 26650000,
"word" : "<silence\/>",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 14,
"start_time" : 26650000,
"end_time" : 29050000,
"word" : "can",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 15,
"start_time" : 29050000,
"end_time" : 31750000,
"word" : "hear",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 16,
"start_time" : 31750000,
"end_time" : 33550000,
"word" : "me",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 17,
"start_time" : 33550000,
"end_time" : 39850000,
"word" : "<silence\/>",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 18,
"start_time" : 39850000,
"end_time" : 46450000,
"word" : "okay",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 19,
"start_time" : 46450000,
"end_time" : 47350000,
"word" : "<silence\/>",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 20,
"start_time" : 47350000,
"end_time" : 49450000,
"word" : "i",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 21,
"start_time" : 49450000,
"end_time" : 52750000,
"word" : "wanted",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 22,
"start_time" : 52750000,
"end_time" : 53650000,
"word" : "to",
"posterior_probability" : 0.9362461010421594,
"channel" : 0
},
{
"time_slot" : 22,
"start_time" : 52750000,
"end_time" : 53650000,
"word" : "the",
"posterior_probability" : 0.06375390219336789,
"channel" : 0
},
{
"time_slot" : 23,
"start_time" : 53650000,
"end_time" : 57250000,
"word" : "call",
"posterior_probability" : 0.973841514002162,
"channel" : 0
},
{
"time_slot" : 23,
"start_time" : 53650000,
"end_time" : 56880000,
"word" : "car",
"posterior_probability" : 0.026158485997024156,
"channel" : 0
},
{
"time_slot" : 24,
"start_time" : 56650000,
"end_time" : 56950000,
"word" : "<silence\/>",
"posterior_probability" : 0.0057991469999294646,
"channel" : 0
},
{
"time_slot" : 24,
"start_time" : 0,
"end_time" : 0,
"word" : "<null\/>",
"posterior_probability" : 0.9942008528246066,
"channel" : 0
},
{
"time_slot" : 25,
"start_time" : 57240000,
"end_time" : 58750000,
"word" : "you",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 26,
"start_time" : 58750000,
"end_time" : 59950000,
"word" : "and",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 27,
"start_time" : 59950000,
"end_time" : 62350000,
"word" : "give",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 28,
"start_time" : 62350000,
"end_time" : 63250000,
"word" : "you",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 29,
"start_time" : 63250000,
"end_time" : 64450000,
"word" : "an",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 30,
"start_time" : 64450000,
"end_time" : 68290000,
"word" : "update",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 31,
"start_time" : 67980000,
"end_time" : 68280000,
"word" : "<silence\/>",
"posterior_probability" : 0.00491605467144139,
"channel" : 0
},
{
"time_slot" : 31,
"start_time" : 0,
"end_time" : 0,
"word" : "<null\/>",
"posterior_probability" : 0.995083945855557,
"channel" : 0
},
{
"time_slot" : 32,
"start_time" : 68650000,
"end_time" : 70150000,
"word" : "i'll",
"posterior_probability" : 0.1827943314478846,
"channel" : 0
},
{
"time_slot" : 32,
"start_time" : 68650000,
"end_time" : 70150000,
"word" : "our",
"posterior_probability" : 0.14940196982948614,
"channel" : 0
},
{
"time_slot" : 32,
"start_time" : 68650000,
"end_time" : 68950000,
"word" : "<silence\/>",
"posterior_probability" : 0.0008166144725752916,
"channel" : 0
},
{
"time_slot" : 32,
"start_time" : 68310000,
"end_time" : 69320000,
"word" : "on",
"posterior_probability" : 0.1552436484222199,
"channel" : 0
},
{
"time_slot" : 32,
"start_time" : 68050000,
"end_time" : 68950000,
"word" : "and",
"posterior_probability" : 0.11349613126680816,
"channel" : 0
},
{
"time_slot" : 32,
"start_time" : 68050000,
"end_time" : 68650000,
"word" : "in",
"posterior_probability" : 0.06527247380490805,
"channel" : 0
},
{
"time_slot" : 32,
"start_time" : 68050000,
"end_time" : 69850000,
"word" : "now",
"posterior_probability" : 0.33297485860065135,
"channel" : 0
},
{
"time_slot" : 33,
"start_time" : 68650000,
"end_time" : 70150000,
"word" : "i'll",
"posterior_probability" : 0.015730519470000235,
"channel" : 0
},
{
"time_slot" : 33,
"start_time" : 68650000,
"end_time" : 70150000,
"word" : "our",
"posterior_probability" : 0.13515226275493714,
"channel" : 0
},
{
"time_slot" : 33,
"start_time" : 68950000,
"end_time" : 70150000,
"word" : "on",
"posterior_probability" : 0.0008166144725752916,
"channel" : 0
},
{
"time_slot" : 33,
"start_time" : 68950000,
"end_time" : 70150000,
"word" : "all",
"posterior_probability" : 0.11349613126680816,
"channel" : 0
},
{
"time_slot" : 33,
"start_time" : 0,
"end_time" : 0,
"word" : "<null\/>",
"posterior_probability" : 0.7348044806451315,
"channel" : 0
},
{
"time_slot" : 34,
"start_time" : 70050000,
"end_time" : 72850000,
"word" : "was",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 35,
"start_time" : 72850000,
"end_time" : 76750000,
"word" : "going",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 36,
"start_time" : 76750000,
"end_time" : 80350000,
"word" : "on",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 37,
"start_time" : 80350000,
"end_time" : 80640000,
"word" : "<silence\/>",
"posterior_probability" : 0.30711117934319165,
"channel" : 0
},
{
"time_slot" : 37,
"start_time" : 0,
"end_time" : 0,
"word" : "<null\/>",
"posterior_probability" : 0.6928888020386428,
"channel" : 0
},
{
"time_slot" : 38,
"start_time" : 80440000,
"end_time" : 82450000,
"word" : "<\/segment>",
"posterior_probability" : 1,
"channel" : 0
}
...
...
{
"channel_id" : 0,
"score" : 0,
"confidence" : 0,
"start" : 0,
"end" : 3750000,
"word" : "<sil\/>"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 3750000,
"end" : 6050000,
"word" : "<s>"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 6050000,
"end" : 8150000,
"word" : "I"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 8150000,
"end" : 10550000,
"word" : "guess"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 10550000,
"end" : 11950000,
"word" : "we"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 11950000,
"end" : 12950000,
"word" : "can"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 12950000,
"end" : 14650000,
"word" : "go"
},
{
"channel_id" : 0,
"score" : -0.0000000002574221,
"confidence" : 1,
"start" : 14650000,
"end" : 16850000,
"word" : "on"
},
{
"channel_id" : 0,
"score" : -0.0014538774,
"confidence" : 0.99854714,
"start" : 16850000,
"end" : 17550000,
"word" : "in"
},
{
"channel_id" : 0,
"score" : -0.0015979912,
"confidence" : 0.99840325,
"start" : 17550000,
"end" : 21850000,
"word" : "time"
},
{
"channel_id" : 0,
"score" : -0.0016018926,
"confidence" : 0.9983994,
"start" : 21850000,
"end" : 26250000,
"word" : "<sil\/>"
},
{
"channel_id" : 0,
"score" : -0.102252305,
"confidence" : 0.9028017,
"start" : 26250000,
"end" : 28950000,
"word" : "can"
},
{
"channel_id" : 0,
"score" : -0.100507334,
"confidence" : 0.9043784,
"start" : 28950000,
"end" : 31950000,
"word" : "hear"
},
{
"channel_id" : 0,
"score" : -0.10048346,
"confidence" : 0.90440005,
"start" : 31950000,
"end" : 34150000,
"word" : "me"
},
{
"channel_id" : 0,
"score" : -0.000000002882713,
"confidence" : 1,
"start" : 34150000,
"end" : 39450000,
"word" : "<sil\/>"
},
{
"channel_id" : 0,
"score" : -0.000011186823,
"confidence" : 0.9999888,
"start" : 39450000,
"end" : 46450000,
"word" : "Okay"
},
{
"channel_id" : 0,
"score" : 0.00000000395712,
"confidence" : 1,
"start" : 46450000,
"end" : 47350000,
"word" : "<sil\/>"
},
{
"channel_id" : 0,
"score" : 0.000000016753798,
"confidence" : 1,
"start" : 47350000,
"end" : 49450000,
"word" : "I"
},
{
"channel_id" : 0,
"score" : -0.1955519,
"confidence" : 0.82238066,
"start" : 49450000,
"end" : 52650000,
"word" : "wanted"
},
{
"channel_id" : 0,
"score" : 0.000000016753798,
"confidence" : 1,
"start" : 52650000,
"end" : 53750000,
"word" : "to"
},
{
"channel_id" : 0,
"score" : 0.000000016753798,
"confidence" : 1,
"start" : 53750000,
"end" : 57250000,
"word" : "call"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 57250000,
"end" : 58750000,
"word" : "you"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 58750000,
"end" : 60350000,
"word" : "and"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 60350000,
"end" : 62450000,
"word" : "give"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 62450000,
"end" : 63350000,
"word" : "you"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 63350000,
"end" : 64250000,
"word" : "an"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 64250000,
"end" : 68750000,
"word" : "update"
},
{
"channel_id" : 0,
"score" : 0.0000000039556407,
"confidence" : 1,
"start" : 68750000,
"end" : 70050000,
"word" : "on"
},
{
"channel_id" : 0,
"score" : -0.0000044112403,
"confidence" : 0.9999956,
"start" : 70050000,
"end" : 73050000,
"word" : "what's"
},
{
"channel_id" : 0,
"score" : 0.0000000039556407,
"confidence" : 1,
"start" : 73050000,
"end" : 76850000,
"word" : "going"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 76850000,
"end" : 80650000,
"word" : "on"
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 0,
"start" : 80650000,
"end" : 80650000,
"word" : "."
},
{
"channel_id" : 0,
"score" : 0,
"confidence" : 1,
"start" : 80650000,
"end" : 82650000,
"word" : "<\/s>"
}
...
...
"variant" : [
{
"phrase" : "I guess we can go on in time <sil\/> can hear me <sil\/> Okay <sil\/> I wanted to call you and give you an update on what's going on.",
"channel" : 0,
"score" : 19212.27,
"confidence" : 0.20302442
},
{
"phrase" : "I guess we can go on in time <sil\/> can hear me <sil\/> Okay <sil\/> I want to call you and give you an update on what's going on.",
"channel" : 0,
"score" : 19207.16,
"confidence" : 0.20096016
},
{
"phrase" : "I guess we can go on in time <sil\/> can you hear me <sil\/> Okay <sil\/> I wanted to call you and give you an update on what's going on.",
"channel" : 0,
"score" : 19204.861,
"confidence" : 0.20003852
},
{
"phrase" : "I guess we can go on in time <sil\/> can you hear me <sil\/> Okay <sil\/> I want to call you and give you an update on what's going on.",
"channel" : 0,
"score" : 19199.752,
"confidence" : 0.19800463
},
{
"phrase" : "I guess we can go on in time <sil\/> can hear me <sil\/> Okay <sil\/> I wanted to call you and give you an update on what's going on.",
"channel" : 0,
"score" : 19199.674,
"confidence" : 0.19797367
}
]
...
...
{
"time_slot" : 0,
"start_time" : 0,
"end_time" : 3750000,
"word" : "_SILENCE_",
"posterior_probability" : 0,
"channel" : 0
},
{
"time_slot" : 1,
"start_time" : 3750000,
"end_time" : 6050000,
"word" : "<s>",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 2,
"start_time" : 6050000,
"end_time" : 8150000,
"word" : "I",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 3,
"start_time" : 8150000,
"end_time" : 10050000,
"word" : "guess",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 4,
"start_time" : 10050000,
"end_time" : 10250000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 4,
"start_time" : 10050000,
"end_time" : 10250000,
"word" : "if",
"posterior_probability" : 0.000000000001097692047105086,
"channel" : 0
},
{
"time_slot" : 4,
"start_time" : 10050000,
"end_time" : 10250000,
"word" : "<sil\/>",
"posterior_probability" : 2.4997528327875485e-21,
"channel" : 0
},
{
"time_slot" : 5,
"start_time" : 10250000,
"end_time" : 10350000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 5,
"start_time" : 10250000,
"end_time" : 10350000,
"word" : "if",
"posterior_probability" : 2.4997528327875485e-21,
"channel" : 0
},
{
"time_slot" : 6,
"start_time" : 10350000,
"end_time" : 10550000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 6,
"start_time" : 10350000,
"end_time" : 10550000,
"word" : "<sil\/>",
"posterior_probability" : 0.0000000000007976631564086393,
"channel" : 0
},
{
"time_slot" : 7,
"start_time" : 10550000,
"end_time" : 10650000,
"word" : "we",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 7,
"start_time" : 10550000,
"end_time" : 10650000,
"word" : "<sil\/>",
"posterior_probability" : 1.1903876594347177e-21,
"channel" : 0
},
{
"time_slot" : 8,
"start_time" : 10650000,
"end_time" : 11250000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 8,
"start_time" : 10650000,
"end_time" : 11250000,
"word" : "we",
"posterior_probability" : 0.000000005323991373268118,
"channel" : 0
},
{
"time_slot" : 8,
"start_time" : 10650000,
"end_time" : 11250000,
"word" : "I",
"posterior_probability" : 0.0000000000000031541523300901196,
"channel" : 0
},
{
"time_slot" : 8,
"start_time" : 10650000,
"end_time" : 11250000,
"word" : "what",
"posterior_probability" : 4.511825827947602e-16,
"channel" : 0
},
{
"time_slot" : 8,
"start_time" : 10650000,
"end_time" : 11250000,
"word" : "where",
"posterior_probability" : 9.41010780470591e-20,
"channel" : 0
},
{
"time_slot" : 9,
"start_time" : 11250000,
"end_time" : 11550000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 9,
"start_time" : 11250000,
"end_time" : 11550000,
"word" : "I",
"posterior_probability" : 1.1903740366070198e-21,
"channel" : 0
},
{
"time_slot" : 10,
"start_time" : 11550000,
"end_time" : 11750000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 10,
"start_time" : 11550000,
"end_time" : 11750000,
"word" : "I",
"posterior_probability" : 4.512772545989491e-16,
"channel" : 0
},
{
"time_slot" : 10,
"start_time" : 11550000,
"end_time" : 11750000,
"word" : "we",
"posterior_probability" : 2.4997528327875485e-21,
"channel" : 0
},
{
"time_slot" : 11,
"start_time" : 11750000,
"end_time" : 11950000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 11,
"start_time" : 11750000,
"end_time" : 11950000,
"word" : "<sil\/>",
"posterior_probability" : 0.00000000000008007755500813061,
"channel" : 0
},
{
"time_slot" : 12,
"start_time" : 11950000,
"end_time" : 12250000,
"word" : "can",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 12,
"start_time" : 11950000,
"end_time" : 12250000,
"word" : "<sil\/>",
"posterior_probability" : 3.42960646792052e-21,
"channel" : 0
},
{
"time_slot" : 12,
"start_time" : 11950000,
"end_time" : 12250000,
"word" : "could",
"posterior_probability" : 1.842152919517877e-23,
"channel" : 0
},
{
"time_slot" : 13,
"start_time" : 12250000,
"end_time" : 12950000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 13,
"start_time" : 12250000,
"end_time" : 12950000,
"word" : "could",
"posterior_probability" : 0.000000005322001422550498,
"channel" : 0
},
{
"time_slot" : 13,
"start_time" : 12250000,
"end_time" : 12950000,
"word" : "<sil\/>",
"posterior_probability" : 1.7677444888718532e-18,
"channel" : 0
},
{
"time_slot" : 14,
"start_time" : 12950000,
"end_time" : 14650000,
"word" : "go",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 15,
"start_time" : 14650000,
"end_time" : 15850000,
"word" : "on",
"posterior_probability" : 0.999999999742578,
"channel" : 0
},
{
"time_slot" : 16,
"start_time" : 15850000,
"end_time" : 16550000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 16,
"start_time" : 15850000,
"end_time" : 16550000,
"word" : "on",
"posterior_probability" : 1.9356503425026671e-28,
"channel" : 0
},
{
"time_slot" : 17,
"start_time" : 16550000,
"end_time" : 16650000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 17,
"start_time" : 16550000,
"end_time" : 16650000,
"word" : "<sil\/>",
"posterior_probability" : 4.5775081673496354e-18,
"channel" : 0
},
{
"time_slot" : 18,
"start_time" : 16650000,
"end_time" : 16850000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 18,
"start_time" : 16650000,
"end_time" : 16850000,
"word" : "<sil\/>",
"posterior_probability" : 7.693133764007473e-24,
"channel" : 0
},
{
"time_slot" : 19,
"start_time" : 16850000,
"end_time" : 17550000,
"word" : "in",
"posterior_probability" : 0.9985471789410968,
"channel" : 0
},
{
"time_slot" : 19,
"start_time" : 16850000,
"end_time" : 17550000,
"word" : "and",
"posterior_probability" : 0.001449420395292837,
"channel" : 0
},
{
"time_slot" : 19,
"start_time" : 16850000,
"end_time" : 17550000,
"word" : "_DELETE_",
"posterior_probability" : 0.000003397466131973464,
"channel" : 0
},
{
"time_slot" : 19,
"start_time" : 16850000,
"end_time" : 17550000,
"word" : "a",
"posterior_probability" : 0.0000000028845730680714527,
"channel" : 0
},
{
"time_slot" : 19,
"start_time" : 16850000,
"end_time" : 17550000,
"word" : "on",
"posterior_probability" : 0.00000000000004401643389419783,
"channel" : 0
},
{
"time_slot" : 19,
"start_time" : 16850000,
"end_time" : 17550000,
"word" : "at",
"posterior_probability" : 0.000000000000003186612474256685,
"channel" : 0
},
{
"time_slot" : 19,
"start_time" : 16850000,
"end_time" : 17550000,
"word" : "to",
"posterior_probability" : 6.2535191806661645e-24,
"channel" : 0
},
{
"time_slot" : 20,
"start_time" : 17550000,
"end_time" : 17850000,
"word" : "time",
"posterior_probability" : 0.9984032848949292,
"channel" : 0
},
{
"time_slot" : 20,
"start_time" : 17550000,
"end_time" : 17850000,
"word" : "_DELETE_",
"posterior_probability" : 0.00159674841632202,
"channel" : 0
},
{
"time_slot" : 20,
"start_time" : 17550000,
"end_time" : 17850000,
"word" : "<sil\/>",
"posterior_probability" : 0.00000004486922440927701,
"channel" : 0
},
{
"time_slot" : 20,
"start_time" : 17550000,
"end_time" : 17850000,
"word" : "a",
"posterior_probability" : 5.236637385734306e-19,
"channel" : 0
},
{
"time_slot" : 20,
"start_time" : 17550000,
"end_time" : 17850000,
"word" : "tom",
"posterior_probability" : 1.1001004626525164e-23,
"channel" : 0
},
{
"time_slot" : 21,
"start_time" : 17850000,
"end_time" : 17950000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 21,
"start_time" : 17850000,
"end_time" : 17950000,
"word" : "<sil\/>",
"posterior_probability" : 0.0000000000008456427956711072,
"channel" : 0
},
{
"time_slot" : 21,
"start_time" : 17850000,
"end_time" : 17950000,
"word" : "tom",
"posterior_probability" : 6.2535191806661645e-24,
"channel" : 0
},
{
"time_slot" : 22,
"start_time" : 17950000,
"end_time" : 21850000,
"word" : "_DELETE_",
"posterior_probability" : 0.9984032156221856,
"channel" : 0
},
{
"time_slot" : 22,
"start_time" : 17950000,
"end_time" : 21850000,
"word" : "tom",
"posterior_probability" : 0.0015505326807412,
"channel" : 0
},
{
"time_slot" : 22,
"start_time" : 17950000,
"end_time" : 21850000,
"word" : "tong",
"posterior_probability" : 0.000026205718954265697,
"channel" : 0
},
{
"time_slot" : 22,
"start_time" : 17950000,
"end_time" : 21850000,
"word" : "time",
"posterior_probability" : 0.00002002583901804666,
"channel" : 0
},
{
"time_slot" : 22,
"start_time" : 17950000,
"end_time" : 21850000,
"word" : "town",
"posterior_probability" : 0.000000000000004058750179897697,
"channel" : 0
},
{
"time_slot" : 23,
"start_time" : 21850000,
"end_time" : 21950000,
"word" : "<sil\/>",
"posterior_probability" : 0.9983993897053142,
"channel" : 0
},
{
"time_slot" : 23,
"start_time" : 21850000,
"end_time" : 21950000,
"word" : "_DELETE_",
"posterior_probability" : 0.0016006232504365277,
"channel" : 0
},
{
"time_slot" : 24,
"start_time" : 21950000,
"end_time" : 22050000,
"word" : "_DELETE_",
"posterior_probability" : 0.9984455354226835,
"channel" : 0
},
{
"time_slot" : 24,
"start_time" : 21950000,
"end_time" : 22050000,
"word" : "<sil\/>",
"posterior_probability" : 0.0015544302573791409,
"channel" : 0
},
{
"time_slot" : 25,
"start_time" : 22050000,
"end_time" : 22150000,
"word" : "_DELETE_",
"posterior_probability" : 0.9999737679266268,
"channel" : 0
},
{
"time_slot" : 25,
"start_time" : 22050000,
"end_time" : 22150000,
"word" : "<sil\/>",
"posterior_probability" : 0.000026205718954265697,
"channel" : 0
},
{
"time_slot" : 26,
"start_time" : 22150000,
"end_time" : 26250000,
"word" : "_DELETE_",
"posterior_probability" : 0.9999800277976596,
"channel" : 0
},
{
"time_slot" : 26,
"start_time" : 22150000,
"end_time" : 26250000,
"word" : "<sil\/>",
"posterior_probability" : 0.000019978112463596095,
"channel" : 0
},
{
"time_slot" : 27,
"start_time" : 26250000,
"end_time" : 26750000,
"word" : "can",
"posterior_probability" : 0.9028017419405316,
"channel" : 0
},
{
"time_slot" : 27,
"start_time" : 26250000,
"end_time" : 26750000,
"word" : "_DELETE_",
"posterior_probability" : 0.09719830586947564,
"channel" : 0
},
{
"time_slot" : 28,
"start_time" : 26750000,
"end_time" : 27050000,
"word" : "_DELETE_",
"posterior_probability" : 0.9028479534715628,
"channel" : 0
},
{
"time_slot" : 28,
"start_time" : 26750000,
"end_time" : 27050000,
"word" : "can",
"posterior_probability" : 0.09715206180531648,
"channel" : 0
},
{
"time_slot" : 28,
"start_time" : 26750000,
"end_time" : 27050000,
"word" : "couldn't",
"posterior_probability" : 0.000000000023772174911405238,
"channel" : 0
},
{
"time_slot" : 28,
"start_time" : 26750000,
"end_time" : 27050000,
"word" : "I",
"posterior_probability" : 0.000000000000123660414034539,
"channel" : 0
},
{
"time_slot" : 29,
"start_time" : 27050000,
"end_time" : 28650000,
"word" : "_DELETE_",
"posterior_probability" : 0.9999537962190962,
"channel" : 0
},
{
"time_slot" : 29,
"start_time" : 27050000,
"end_time" : 28650000,
"word" : "can",
"posterior_probability" : 0.000046183796522294467,
"channel" : 0
},
{
"time_slot" : 29,
"start_time" : 27050000,
"end_time" : 28650000,
"word" : "couldn't",
"posterior_probability" : 0.00000000023070124890184347,
"channel" : 0
},
{
"time_slot" : 30,
"start_time" : 28650000,
"end_time" : 28950000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 30,
"start_time" : 28650000,
"end_time" : 28950000,
"word" : "<sil\/>",
"posterior_probability" : 0.000000000001724357873770499,
"channel" : 0
},
{
"time_slot" : 31,
"start_time" : 28950000,
"end_time" : 29350000,
"word" : "hear",
"posterior_probability" : 0.9043784797899946,
"channel" : 0
},
{
"time_slot" : 31,
"start_time" : 28950000,
"end_time" : 29350000,
"word" : "you",
"posterior_probability" : 0.09559992017498804,
"channel" : 0
},
{
"time_slot" : 31,
"start_time" : 28950000,
"end_time" : 29350000,
"word" : "_DELETE_",
"posterior_probability" : 0.00002157688616222485,
"channel" : 0
},
{
"time_slot" : 32,
"start_time" : 29350000,
"end_time" : 29650000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 32,
"start_time" : 29350000,
"end_time" : 29650000,
"word" : "<sil\/>",
"posterior_probability" : 4.089593108327641e-26,
"channel" : 0
},
{
"time_slot" : 33,
"start_time" : 29650000,
"end_time" : 31950000,
"word" : "_DELETE_",
"posterior_probability" : 0.90437847305185,
"channel" : 0
},
{
"time_slot" : 33,
"start_time" : 29650000,
"end_time" : 31950000,
"word" : "hear",
"posterior_probability" : 0.09562153018873204,
"channel" : 0
},
{
"time_slot" : 34,
"start_time" : 31950000,
"end_time" : 32050000,
"word" : "me",
"posterior_probability" : 0.9044000690634708,
"channel" : 0
},
{
"time_slot" : 34,
"start_time" : 31950000,
"end_time" : 32050000,
"word" : "_DELETE_",
"posterior_probability" : 0.09559994296778788,
"channel" : 0
},
{
"time_slot" : 34,
"start_time" : 31950000,
"end_time" : 32050000,
"word" : "<sil\/>",
"posterior_probability" : 7.58330672137358e-19,
"channel" : 0
},
{
"time_slot" : 35,
"start_time" : 32050000,
"end_time" : 34150000,
"word" : "_DELETE_",
"posterior_probability" : 0.904400048848554,
"channel" : 0
},
{
"time_slot" : 35,
"start_time" : 32050000,
"end_time" : 34150000,
"word" : "me",
"posterior_probability" : 0.09559994296778788,
"channel" : 0
},
{
"time_slot" : 36,
"start_time" : 34150000,
"end_time" : 39450000,
"word" : "<sil\/>",
"posterior_probability" : 0.999999997117287,
"channel" : 0
},
{
"time_slot" : 37,
"start_time" : 39450000,
"end_time" : 45450000,
"word" : "Okay",
"posterior_probability" : 0.9999888132395416,
"channel" : 0
},
{
"time_slot" : 37,
"start_time" : 39450000,
"end_time" : 45450000,
"word" : "ok",
"posterior_probability" : 0.000011190717578296304,
"channel" : 0
},
{
"time_slot" : 38,
"start_time" : 45450000,
"end_time" : 46450000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 38,
"start_time" : 45450000,
"end_time" : 46450000,
"word" : "I",
"posterior_probability" : 9.567729161265924e-23,
"channel" : 0
},
{
"time_slot" : 39,
"start_time" : 46450000,
"end_time" : 46650000,
"word" : "<sil\/>",
"posterior_probability" : 1.00000000395712,
"channel" : 0
},
{
"time_slot" : 40,
"start_time" : 46650000,
"end_time" : 46950000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 40,
"start_time" : 46650000,
"end_time" : 46950000,
"word" : "I",
"posterior_probability" : 0.000000000000028320501166416315,
"channel" : 0
},
{
"time_slot" : 41,
"start_time" : 46950000,
"end_time" : 47350000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 41,
"start_time" : 46950000,
"end_time" : 47350000,
"word" : "<sil\/>",
"posterior_probability" : 0.000000000000028320501166416315,
"channel" : 0
},
{
"time_slot" : 42,
"start_time" : 47350000,
"end_time" : 49450000,
"word" : "I",
"posterior_probability" : 1.0000000167537986,
"channel" : 0
},
{
"time_slot" : 43,
"start_time" : 49450000,
"end_time" : 51850000,
"word" : "wanted",
"posterior_probability" : 0.822380659209675,
"channel" : 0
},
{
"time_slot" : 43,
"start_time" : 49450000,
"end_time" : 51850000,
"word" : "want",
"posterior_probability" : 0.17761935754412272,
"channel" : 0
},
{
"time_slot" : 44,
"start_time" : 51850000,
"end_time" : 51950000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 44,
"start_time" : 51850000,
"end_time" : 51950000,
"word" : "to",
"posterior_probability" : 3.431556375673839e-21,
"channel" : 0
},
{
"time_slot" : 45,
"start_time" : 51950000,
"end_time" : 52450000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 45,
"start_time" : 51950000,
"end_time" : 52450000,
"word" : "you",
"posterior_probability" : 0.00000000000001522241147037374,
"channel" : 0
},
{
"time_slot" : 45,
"start_time" : 51950000,
"end_time" : 52450000,
"word" : "to",
"posterior_probability" : 2.9792239555101523e-16,
"channel" : 0
},
{
"time_slot" : 46,
"start_time" : 52450000,
"end_time" : 52650000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 46,
"start_time" : 52450000,
"end_time" : 52650000,
"word" : "<sil\/>",
"posterior_probability" : 3.431556375673839e-21,
"channel" : 0
},
{
"time_slot" : 47,
"start_time" : 52650000,
"end_time" : 53450000,
"word" : "to",
"posterior_probability" : 1.0000000167537986,
"channel" : 0
},
{
"time_slot" : 47,
"start_time" : 52650000,
"end_time" : 53450000,
"word" : "the",
"posterior_probability" : 0.0000000011971779940339015,
"channel" : 0
},
{
"time_slot" : 48,
"start_time" : 53450000,
"end_time" : 53750000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 48,
"start_time" : 53450000,
"end_time" : 53750000,
"word" : "<sil\/>",
"posterior_probability" : 0.000000000027133456261556822,
"channel" : 0
},
{
"time_slot" : 49,
"start_time" : 53750000,
"end_time" : 57250000,
"word" : "call",
"posterior_probability" : 1.0000000167537986,
"channel" : 0
},
{
"time_slot" : 49,
"start_time" : 53750000,
"end_time" : 57250000,
"word" : "called",
"posterior_probability" : 6.470402772569521e-20,
"channel" : 0
},
{
"time_slot" : 50,
"start_time" : 57250000,
"end_time" : 57550000,
"word" : "you",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 51,
"start_time" : 57550000,
"end_time" : 58350000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 51,
"start_time" : 57550000,
"end_time" : 58350000,
"word" : "you",
"posterior_probability" : 0.0000000012244607370013503,
"channel" : 0
},
{
"time_slot" : 52,
"start_time" : 58350000,
"end_time" : 58750000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 52,
"start_time" : 58350000,
"end_time" : 58750000,
"word" : "<sil\/>",
"posterior_probability" : 2.4637700183523362e-20,
"channel" : 0
},
{
"time_slot" : 53,
"start_time" : 58750000,
"end_time" : 58850000,
"word" : "and",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 53,
"start_time" : 58750000,
"end_time" : 58850000,
"word" : "<sil\/>",
"posterior_probability" : 8.252333504553301e-16,
"channel" : 0
},
{
"time_slot" : 54,
"start_time" : 58850000,
"end_time" : 59950000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 54,
"start_time" : 58850000,
"end_time" : 59950000,
"word" : "can",
"posterior_probability" : 0.00000000000013460437663022564,
"channel" : 0
},
{
"time_slot" : 54,
"start_time" : 58850000,
"end_time" : 59950000,
"word" : "and",
"posterior_probability" : 8.252333504553301e-16,
"channel" : 0
},
{
"time_slot" : 55,
"start_time" : 59950000,
"end_time" : 60350000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 55,
"start_time" : 59950000,
"end_time" : 60350000,
"word" : "<sil\/>",
"posterior_probability" : 0.0000000000013123728712492394,
"channel" : 0
},
{
"time_slot" : 56,
"start_time" : 60350000,
"end_time" : 62450000,
"word" : "give",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 57,
"start_time" : 62450000,
"end_time" : 63350000,
"word" : "you",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 58,
"start_time" : 63350000,
"end_time" : 63550000,
"word" : "an",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 58,
"start_time" : 63350000,
"end_time" : 63550000,
"word" : "<sil\/>",
"posterior_probability" : 2.7693254396692766e-16,
"channel" : 0
},
{
"time_slot" : 59,
"start_time" : 63550000,
"end_time" : 63650000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 59,
"start_time" : 63550000,
"end_time" : 63650000,
"word" : "an",
"posterior_probability" : 0.00000000003571772165147594,
"channel" : 0
},
{
"time_slot" : 59,
"start_time" : 63550000,
"end_time" : 63650000,
"word" : "<sil\/>",
"posterior_probability" : 8.957495215467934e-28,
"channel" : 0
},
{
"time_slot" : 60,
"start_time" : 63650000,
"end_time" : 64250000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 60,
"start_time" : 63650000,
"end_time" : 64250000,
"word" : "an",
"posterior_probability" : 8.957495215467934e-28,
"channel" : 0
},
{
"time_slot" : 61,
"start_time" : 64250000,
"end_time" : 64350000,
"word" : "update",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 62,
"start_time" : 64350000,
"end_time" : 64550000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 62,
"start_time" : 64350000,
"end_time" : 64550000,
"word" : "<sil\/>",
"posterior_probability" : 0.00000000003571744914792522,
"channel" : 0
},
{
"time_slot" : 63,
"start_time" : 64550000,
"end_time" : 68450000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 63,
"start_time" : 64550000,
"end_time" : 68450000,
"word" : "update",
"posterior_probability" : 0.00000000003571744914792522,
"channel" : 0
},
{
"time_slot" : 64,
"start_time" : 68450000,
"end_time" : 68550000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 64,
"start_time" : 68450000,
"end_time" : 68550000,
"word" : "<sil\/>",
"posterior_probability" : 3.806619914055471e-24,
"channel" : 0
},
{
"time_slot" : 65,
"start_time" : 68550000,
"end_time" : 68750000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 65,
"start_time" : 68550000,
"end_time" : 68750000,
"word" : "<sil\/>",
"posterior_probability" : 0.00000000015641112281432676,
"channel" : 0
},
{
"time_slot" : 66,
"start_time" : 68750000,
"end_time" : 70050000,
"word" : "on",
"posterior_probability" : 1.0000000039556407,
"channel" : 0
},
{
"time_slot" : 66,
"start_time" : 68750000,
"end_time" : 70050000,
"word" : "know",
"posterior_probability" : 1.2716997701061177e-19,
"channel" : 0
},
{
"time_slot" : 67,
"start_time" : 70050000,
"end_time" : 70250000,
"word" : "what's",
"posterior_probability" : 0.999995588769432,
"channel" : 0
},
{
"time_slot" : 67,
"start_time" : 70050000,
"end_time" : 70250000,
"word" : "<sil\/>",
"posterior_probability" : 0.0000044151862087921855,
"channel" : 0
},
{
"time_slot" : 68,
"start_time" : 70250000,
"end_time" : 70450000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 68,
"start_time" : 70250000,
"end_time" : 70450000,
"word" : "<sil\/>",
"posterior_probability" : 1.473336786630198e-18,
"channel" : 0
},
{
"time_slot" : 68,
"start_time" : 70250000,
"end_time" : 70450000,
"word" : "was",
"posterior_probability" : 1.2716997701061177e-19,
"channel" : 0
},
{
"time_slot" : 69,
"start_time" : 70450000,
"end_time" : 72650000,
"word" : "_DELETE_",
"posterior_probability" : 0.9999955882182808,
"channel" : 0
},
{
"time_slot" : 69,
"start_time" : 70450000,
"end_time" : 72650000,
"word" : "what's",
"posterior_probability" : 0.000004419651754181,
"channel" : 0
},
{
"time_slot" : 69,
"start_time" : 70450000,
"end_time" : 72650000,
"word" : "was",
"posterior_probability" : 0.000000008810838966828258,
"channel" : 0
},
{
"time_slot" : 70,
"start_time" : 72650000,
"end_time" : 72750000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 70,
"start_time" : 72650000,
"end_time" : 72750000,
"word" : "<sil\/>",
"posterior_probability" : 1.2036911064636818e-18,
"channel" : 0
},
{
"time_slot" : 71,
"start_time" : 72750000,
"end_time" : 73050000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 71,
"start_time" : 72750000,
"end_time" : 73050000,
"word" : "<sil\/>",
"posterior_probability" : 0.000000004308441537475288,
"channel" : 0
},
{
"time_slot" : 72,
"start_time" : 73050000,
"end_time" : 76850000,
"word" : "going",
"posterior_probability" : 1.0000000039556407,
"channel" : 0
},
{
"time_slot" : 73,
"start_time" : 76850000,
"end_time" : 78450000,
"word" : "on",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 74,
"start_time" : 78450000,
"end_time" : 80650000,
"word" : "_DELETE_",
"posterior_probability" : 1,
"channel" : 0
},
{
"time_slot" : 74,
"start_time" : 78450000,
"end_time" : 80650000,
"word" : "on",
"posterior_probability" : 1.0016773250781864e-20,
"channel" : 0
},
{
"time_slot" : 75,
"start_time" : 80650000,
"end_time" : 80850000,
"word" : "<\/s>",
"posterior_probability" : 1,
"channel" : 0
}
...
Example of new generation realtime stream processing Speech To Text
output:
(results contain 4 sentences, i.e. the sentence_info array has 4 elements...
and the n_best_result contains 4 phrase_variants)
Example
{
"result": {
"version": 5,
"name": "SpeechRecognitionOnlineResult",
"model": "EN_US_5",
"is_last": true,
"delete_n_words": 0,
"silence_length": 0,
"one_best_result": {
"segmentation": [
{
"channel_id": 0,
"score": 0,
"confidence": 0,
"start": 0,
"end": 5100000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 16.69739,
"confidence": 8.6746855,
"start": 5100000,
"end": 6300000,
"word": "<segment>"
},
{
"channel_id": 0,
"score": 8.276354,
"confidence": 16.829815,
"start": 6300000,
"end": 7800000,
"word": "i"
},
{
"channel_id": 0,
"score": 13.861362,
"confidence": 30.684898,
"start": 7800000,
"end": 10200000,
"word": "guess"
},
{
"channel_id": 0,
"score": 5.3039703,
"confidence": 35.9949,
"start": 10200000,
"end": 11700000,
"word": "we"
},
{
"channel_id": 0,
"score": 5.676548,
"confidence": 41.633205,
"start": 11700000,
"end": 12600000,
"word": "can"
},
{
"channel_id": 0,
"score": 9.360081,
"confidence": 51.079575,
"start": 12600000,
"end": 14400000,
"word": "go"
},
{
"channel_id": 0,
"score": 11.62117,
"confidence": 62.52499,
"start": 14400000,
"end": 16500000,
"word": "on"
},
{
"channel_id": 0,
"score": 7.0505524,
"confidence": 69.69626,
"start": 16500000,
"end": 17700000,
"word": "and"
},
{
"channel_id": 0,
"score": 11.8624115,
"confidence": 81.689224,
"start": 17700000,
"end": 21900000,
"word": "tom"
},
{
"channel_id": 0,
"score": 47.84456,
"confidence": 129.50972,
"start": 21900000,
"end": 26700000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 12.641907,
"confidence": 142.035,
"start": 26700000,
"end": 29100000,
"word": "can"
},
{
"channel_id": 0,
"score": 16.164597,
"confidence": 158.22461,
"start": 29100000,
"end": 31800000,
"word": "hear"
},
{
"channel_id": 0,
"score": 14.25383,
"confidence": 172.59941,
"start": 31800000,
"end": 33600000,
"word": "me"
},
{
"channel_id": 0,
"score": 45.672592,
"confidence": 217.33438,
"start": 33600000,
"end": 37800000,
"word": "</segment>"
},
{
"channel_id": 0,
"score": 0,
"confidence": 0,
"start": 37800000,
"end": 38400000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 18.455282,
"confidence": 10.441687,
"start": 38400000,
"end": 39600000,
"word": "<segment>"
},
{
"channel_id": 0,
"score": 39.1977,
"confidence": 49.599285,
"start": 39600000,
"end": 46200000,
"word": "okay"
},
{
"channel_id": 0,
"score": 8.169598,
"confidence": 57.79995,
"start": 46200000,
"end": 47400000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 8.103287,
"confidence": 65.8135,
"start": 47400000,
"end": 49200000,
"word": "i"
},
{
"channel_id": 0,
"score": 19.919518,
"confidence": 85.66101,
"start": 49200000,
"end": 52500000,
"word": "wanted"
},
{
"channel_id": 0,
"score": 5.430809,
"confidence": 91.16066,
"start": 52500000,
"end": 53700000,
"word": "to"
},
{
"channel_id": 0,
"score": 10.221802,
"confidence": 101.333206,
"start": 53700000,
"end": 57000000,
"word": "call"
},
{
"channel_id": 0,
"score": 13.082092,
"confidence": 114.39673,
"start": 57000000,
"end": 58800000,
"word": "you"
},
{
"channel_id": 0,
"score": 4.9276657,
"confidence": 119.32156,
"start": 58800000,
"end": 59700000,
"word": "and"
},
{
"channel_id": 0,
"score": 12.460022,
"confidence": 131.8381,
"start": 59700000,
"end": 62100000,
"word": "give"
},
{
"channel_id": 0,
"score": 12.44931,
"confidence": 144.1773,
"start": 62100000,
"end": 63300000,
"word": "you"
},
{
"channel_id": 0,
"score": 4.1338806,
"confidence": 148.41356,
"start": 63300000,
"end": 64500000,
"word": "an"
},
{
"channel_id": 0,
"score": 19.068665,
"confidence": 167.48984,
"start": 64500000,
"end": 68700000,
"word": "update"
},
{
"channel_id": 0,
"score": 6.667557,
"confidence": 174.16838,
"start": 68700000,
"end": 69900000,
"word": "on"
},
{
"channel_id": 0,
"score": 3.542862,
"confidence": 177.66133,
"start": 69900000,
"end": 72600000,
"word": "what's"
},
{
"channel_id": 0,
"score": 24.47966,
"confidence": 202.15329,
"start": 72600000,
"end": 76800000,
"word": "going"
},
{
"channel_id": 0,
"score": 19.660477,
"confidence": 221.95056,
"start": 76800000,
"end": 80400000,
"word": "on"
},
{
"channel_id": 0,
"score": 37.938446,
"confidence": 259.89902,
"start": 80400000,
"end": 85200000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 10.720428,
"confidence": 270.46655,
"start": 85200000,
"end": 87600000,
"word": "now"
},
{
"channel_id": 0,
"score": 7.797577,
"confidence": 278.27808,
"start": 87600000,
"end": 90300000,
"word": "they're"
},
{
"channel_id": 0,
"score": 6.487152,
"confidence": 284.73175,
"start": 90300000,
"end": 92100000,
"word": "not"
},
{
"channel_id": 0,
"score": 14.677246,
"confidence": 299.42725,
"start": 92100000,
"end": 94500000,
"word": "gonna"
},
{
"channel_id": 0,
"score": 26.44159,
"confidence": 325.86304,
"start": 94500000,
"end": 99600000,
"word": "distribute"
},
{
"channel_id": 0,
"score": 11.219635,
"confidence": 337.0916,
"start": 99600000,
"end": 101700000,
"word": "this"
},
{
"channel_id": 0,
"score": 0.7121277,
"confidence": 337.80374,
"start": 101700000,
"end": 102000000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 25.454468,
"confidence": 363.279,
"start": 102000000,
"end": 106800000,
"word": "publicly"
},
{
"channel_id": 0,
"score": 7.0868835,
"confidence": 370.41168,
"start": 106800000,
"end": 108900000,
"word": "like"
},
{
"channel_id": 0,
"score": 9.736755,
"confidence": 380.10986,
"start": 108900000,
"end": 111300000,
"word": "that"
},
{
"channel_id": 0,
"score": 13.583221,
"confidence": 393.62146,
"start": 111300000,
"end": 115200000,
"word": "talking"
},
{
"channel_id": 0,
"score": 20.57788,
"confidence": 414.2678,
"start": 115200000,
"end": 118500000,
"word": "about"
},
{
"channel_id": 0,
"score": 1.2673645,
"confidence": 415.4958,
"start": 118500000,
"end": 119400000,
"word": "is"
},
{
"channel_id": 0,
"score": 15.287842,
"confidence": 430.81738,
"start": 119400000,
"end": 122400000,
"word": "gotta"
},
{
"channel_id": 0,
"score": 19.368042,
"confidence": 450.21445,
"start": 122400000,
"end": 126000000,
"word": "be"
},
{
"channel_id": 0,
"score": 10.876678,
"confidence": 461.06198,
"start": 126000000,
"end": 128700000,
"word": "for"
},
{
"channel_id": 0,
"score": 5.394684,
"confidence": 466.4601,
"start": 128700000,
"end": 129600000,
"word": "it"
},
{
"channel_id": 0,
"score": 7.067322,
"confidence": 473.54886,
"start": 129600000,
"end": 130800000,
"word": "to"
},
{
"channel_id": 0,
"score": 8.253143,
"confidence": 481.79977,
"start": 130800000,
"end": 132000000,
"word": "the"
},
{
"channel_id": 0,
"score": 36.52957,
"confidence": 518.32117,
"start": 132000000,
"end": 138900000,
"word": "educational"
},
{
"channel_id": 0,
"score": 22.771606,
"confidence": 541.20184,
"start": 138900000,
"end": 144300000,
"word": "system"
},
{
"channel_id": 0,
"score": 34.178772,
"confidence": 575.3851,
"start": 144300000,
"end": 148800000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 10.664307,
"confidence": 585.8751,
"start": 148800000,
"end": 150900000,
"word": "and"
},
{
"channel_id": 0,
"score": 11.231689,
"confidence": 597.19684,
"start": 150900000,
"end": 153300000,
"word": "what"
},
{
"channel_id": 0,
"score": 11.060608,
"confidence": 608.1842,
"start": 153300000,
"end": 155100000,
"word": "they're"
},
{
"channel_id": 0,
"score": 17.311401,
"confidence": 625.51544,
"start": 155100000,
"end": 157800000,
"word": "doing"
},
{
"channel_id": 0,
"score": 6.6401978,
"confidence": 632.1533,
"start": 157800000,
"end": 158700000,
"word": "is"
},
{
"channel_id": 0,
"score": 0.7922363,
"confidence": 632.94556,
"start": 158700000,
"end": 159000000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 14.342102,
"confidence": 647.2899,
"start": 159000000,
"end": 162000000,
"word": "trying"
},
{
"channel_id": 0,
"score": 2.007141,
"confidence": 649.25183,
"start": 162000000,
"end": 162600000,
"word": "to"
},
{
"channel_id": 0,
"score": 14.18512,
"confidence": 663.4443,
"start": 162600000,
"end": 164700000,
"word": "do"
},
{
"channel_id": 0,
"score": 6.255188,
"confidence": 669.76855,
"start": 164700000,
"end": 165600000,
"word": "a"
},
{
"channel_id": 0,
"score": 0.87890625,
"confidence": 670.64746,
"start": 165600000,
"end": 165900000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 22.395508,
"confidence": 693.0293,
"start": 165900000,
"end": 170400000,
"word": "study"
},
{
"channel_id": 0,
"score": 12.259399,
"confidence": 705.3145,
"start": 170400000,
"end": 173700000,
"word": "of"
},
{
"channel_id": 0,
"score": 0.16644287,
"confidence": 705.48096,
"start": 173700000,
"end": 174000000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 27.776672,
"confidence": 733.185,
"start": 174000000,
"end": 178200000,
"word": "human"
},
{
"channel_id": 0,
"score": 22.33496,
"confidence": 755.5939,
"start": 178200000,
"end": 182700000,
"word": "boy"
},
{
"channel_id": 0,
"score": 0.8931885,
"confidence": 756.4684,
"start": 182700000,
"end": 183900000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 8.859314,
"confidence": 765.2876,
"start": 183900000,
"end": 186900000,
"word": "saying"
},
{
"channel_id": 0,
"score": 1.2914429,
"confidence": 766.57904,
"start": 186900000,
"end": 187200000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 11.308533,
"confidence": 777.8831,
"start": 187200000,
"end": 189600000,
"word": "all"
},
{
"channel_id": 0,
"score": 2.2028809,
"confidence": 780.0724,
"start": 189600000,
"end": 190200000,
"word": "of"
},
{
"channel_id": 0,
"score": 13.169312,
"confidence": 793.26733,
"start": 190200000,
"end": 192000000,
"word": "that"
},
{
"channel_id": 0,
"score": 8.349609,
"confidence": 801.595,
"start": 192000000,
"end": 193800000,
"word": "kind"
},
{
"channel_id": 0,
"score": 11.52417,
"confidence": 813.0734,
"start": 193800000,
"end": 195000000,
"word": "of"
},
{
"channel_id": 0,
"score": 20.192566,
"confidence": 833.2891,
"start": 195000000,
"end": 198600000,
"word": "stuff"
},
{
"channel_id": 0,
"score": 21.552979,
"confidence": 855.00226,
"start": 198600000,
"end": 203100000,
"word": "so"
},
{
"channel_id": 0,
"score": 49.116577,
"confidence": 903.30774,
"start": 203100000,
"end": 207300000,
"word": "</segment>"
},
{
"channel_id": 0,
"score": 0,
"confidence": 0,
"start": 207300000,
"end": 208900000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 8.194822,
"confidence": 0.18945026,
"start": 208900000,
"end": 209500000,
"word": "<segment>"
},
{
"channel_id": 0,
"score": 4.0293026,
"confidence": 4.1722536,
"start": 209500000,
"end": 211300000,
"word": "you"
},
{
"channel_id": 0,
"score": 9.855663,
"confidence": 13.860518,
"start": 211300000,
"end": 212800000,
"word": "know"
},
{
"channel_id": 0,
"score": 2.9023151,
"confidence": 16.869112,
"start": 212800000,
"end": 214600000,
"word": "its"
},
{
"channel_id": 0,
"score": 8.146326,
"confidence": 25.06319,
"start": 214600000,
"end": 216400000,
"word": "a"
},
{
"channel_id": 0,
"score": 16.729027,
"confidence": 41.750168,
"start": 216400000,
"end": 220300000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 14.972729,
"confidence": 56.758835,
"start": 220300000,
"end": 224500000,
"word": "strange"
},
{
"channel_id": 0,
"score": 3.4374466,
"confidence": 60.13023,
"start": 224500000,
"end": 227200000,
"word": "cause"
},
{
"channel_id": 0,
"score": 0.8110428,
"confidence": 60.90163,
"start": 227200000,
"end": 228100000,
"word": "i"
},
{
"channel_id": 0,
"score": 7.21756,
"confidence": 68.05884,
"start": 228100000,
"end": 229000000,
"word": "i"
},
{
"channel_id": 0,
"score": 14.390205,
"confidence": 82.550964,
"start": 229000000,
"end": 231400000,
"word": "got"
},
{
"channel_id": 0,
"score": 17.486961,
"confidence": 99.97161,
"start": 231400000,
"end": 235000000,
"word": "thirty"
},
{
"channel_id": 0,
"score": 31.280045,
"confidence": 131.41156,
"start": 235000000,
"end": 239500000,
"word": "minutes"
},
{
"channel_id": 0,
"score": 37.01233,
"confidence": 167.74713,
"start": 239500000,
"end": 243400000,
"word": "</segment>"
},
{
"channel_id": 0,
"score": 0,
"confidence": 0,
"start": 243400000,
"end": 245100000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 8.002458,
"confidence": -0.007990837,
"start": 245100000,
"end": 245700000,
"word": "<segment>"
},
{
"channel_id": 0,
"score": 16.767956,
"confidence": 16.677662,
"start": 245700000,
"end": 248400000,
"word": "and"
},
{
"channel_id": 0,
"score": 11.158337,
"confidence": 27.82969,
"start": 248400000,
"end": 250500000,
"word": "they'll"
},
{
"channel_id": 0,
"score": 7.239273,
"confidence": 35.050312,
"start": 250500000,
"end": 252300000,
"word": "let"
},
{
"channel_id": 0,
"score": 10.675056,
"confidence": 45.723152,
"start": 252300000,
"end": 253800000,
"word": "me"
},
{
"channel_id": 0,
"score": 12.171387,
"confidence": 57.883305,
"start": 253800000,
"end": 256500000,
"word": "know"
},
{
"channel_id": 0,
"score": 8.148384,
"confidence": 65.97767,
"start": 256500000,
"end": 258300000,
"word": "when"
},
{
"channel_id": 0,
"score": 0.92894745,
"confidence": 66.91624,
"start": 258300000,
"end": 258900000,
"word": "uh"
},
{
"channel_id": 0,
"score": 20.644852,
"confidence": 87.383896,
"start": 258900000,
"end": 261900000,
"word": "thirty"
},
{
"channel_id": 0,
"score": 22.643051,
"confidence": 110.23555,
"start": 261900000,
"end": 265200000,
"word": "minutes"
},
{
"channel_id": 0,
"score": 12.68277,
"confidence": 122.89795,
"start": 265200000,
"end": 267600000,
"word": "is"
},
{
"channel_id": 0,
"score": 25.152252,
"confidence": 148.09625,
"start": 267600000,
"end": 273300000,
"word": "almost"
},
{
"channel_id": 0,
"score": 12.658997,
"confidence": 160.8605,
"start": 273300000,
"end": 276000000,
"word": "up"
},
{
"channel_id": 0,
"score": 23.381332,
"confidence": 184.23932,
"start": 276000000,
"end": 278700000,
"word": "<silence/>"
},
{
"channel_id": 0,
"score": 3.9283752,
"confidence": 188.04039,
"start": 278700000,
"end": 281100000,
"word": "or"
},
{
"channel_id": 0,
"score": 3.7181091,
"confidence": 191.78902,
"start": 281100000,
"end": 282900000,
"word": "let"
},
{
"channel_id": 0,
"score": 6.064743,
"confidence": 197.8672,
"start": 282900000,
"end": 284700000,
"word": "us"
},
{
"channel_id": 0,
"score": 8.611694,
"confidence": 206.41795,
"start": 284700000,
"end": 287100000,
"word": "bow"
},
{
"channel_id": 0,
"score": 17.111755,
"confidence": 223.65399,
"start": 287100000,
"end": 290700000,
"word": "no"
},
{
"channel_id": 0,
"score": 41.6261,
"confidence": 264.22202,
"start": 290700000,
"end": 294900000,
"word": "</segment>"
}
],
"sentence_info": [
{
"confidence": 0.928772
},
{
"confidence": 0.8764362
},
{
"confidence": 0.818197
},
{
"confidence": 0.90403795
}
]
},
"n_best_result": {
"phrase_variants": [
{
"variant": [
{
"phrase": "i guess we can go on and tom can hear me",
"channel": 0,
"score": 522.73157,
"confidence": 0.20116612
},
{
"phrase": "i guess we can go on a town can hear me",
"channel": 0,
"score": 519.6558,
"confidence": 0.19993244
},
{
"phrase": "i guess we can go on and tong can hear me",
"channel": 0,
"score": 519.6204,
"confidence": 0.19991829
},
{
"phrase": "i guess we can go on and pong can hear me",
"channel": 0,
"score": 519.10974,
"confidence": 0.19971421
},
{
"phrase": "i guess we can gone and tom can hear me",
"channel": 0,
"score": 517.99347,
"confidence": 0.19926885
}
]
},
{
"variant": [
{
"phrase": "okay i wanted to call you and give you an update on what's going on now they're not gonna distribute this publicly like that talking about is gotta be for it to the educational system and what they're doing is trying to do a study of human boy saying all of that kind of stuff so",
"channel": 0,
"score": 2103.9211,
"confidence": 0.20009224
},
{
"phrase": "okay i wanted to call you and give you an update on what's going on now they're not going to distribute this publicly like that talking about is gotta be for it to the educational system and what they're doing is trying to do a study of human boy saying all of that kind of stuff so",
"channel": 0,
"score": 2103.8467,
"confidence": 0.20006247
},
{
"phrase": "okay i wanted to call you and give you an update on what's going on now they're not gonna distribute this publicly rack that talking about is gotta be for it to the educational system and what they're doing is trying to do a study of human boy saying all of that kind of stuff so",
"channel": 0,
"score": 2103.5945,
"confidence": 0.19996156
},
{
"phrase": "okay i wanted to call you and give you an update on what's going on now they're not gonna distribute this publicly like that talking about is gotta be for it to the educational system and what they're doing is trying to do a study of human boy he's saying all of that kind of stuff so",
"channel": 0,
"score": 2103.571,
"confidence": 0.19995221
},
{
"phrase": "okay i wanted to call you and give you an update on what's going on now they're not going to distribute this publicly rack that talking about is gotta be for it to the educational system and what they're doing is trying to do a study of human boy saying all of that kind of stuff so",
"channel": 0,
"score": 2103.52,
"confidence": 0.19993182
}
]
},
{
"variant": [
{
"phrase": "you know its a strange cause i i got thirty minutes",
"channel": 0,
"score": 408.91052,
"confidence": 0.2003568
},
{
"phrase": "you know its a strange sizing i got thirty minutes",
"channel": 0,
"score": 408.1031,
"confidence": 0.20003352
},
{
"phrase": "you know is a strange cause i i got thirty minutes",
"channel": 0,
"score": 408.07657,
"confidence": 0.2000229
},
{
"phrase": "you know its a strange causing i got thirty minutes",
"channel": 0,
"score": 407.7359,
"confidence": 0.19988668
},
{
"phrase": "you know is a strange sizing i got thirty minutes",
"channel": 0,
"score": 407.2691,
"confidence": 0.19970015
}
]
},
{
"variant": [
{
"phrase": "and they'll let me know when uh thirty minutes is almost up or let us bow no",
"channel": 0,
"score": 630.6306,
"confidence": 0.20051973
},
{
"phrase": "and they'll let me know when a thirty minutes is almost up or let us bow no",
"channel": 0,
"score": 629.8976,
"confidence": 0.20022595
},
{
"phrase": "and they'll let me know when the thirty minutes is almost up or let us bow no",
"channel": 0,
"score": 629.74036,
"confidence": 0.20016299
},
{
"phrase": "and now let me know when uh thirty minutes is almost up or let us bow no",
"channel": 0,
"score": 628.41705,
"confidence": 0.19963396
},
{
"phrase": "and they let me know when uh thirty minutes is almost up or let us bow no",
"channel": 0,
"score": 627.975,
"confidence": 0.19945751
}
]
}
]
}
}
}