Speech to Text Overview
Phonexia Speech to Text (STT) converts speech in audio signals into plain text.
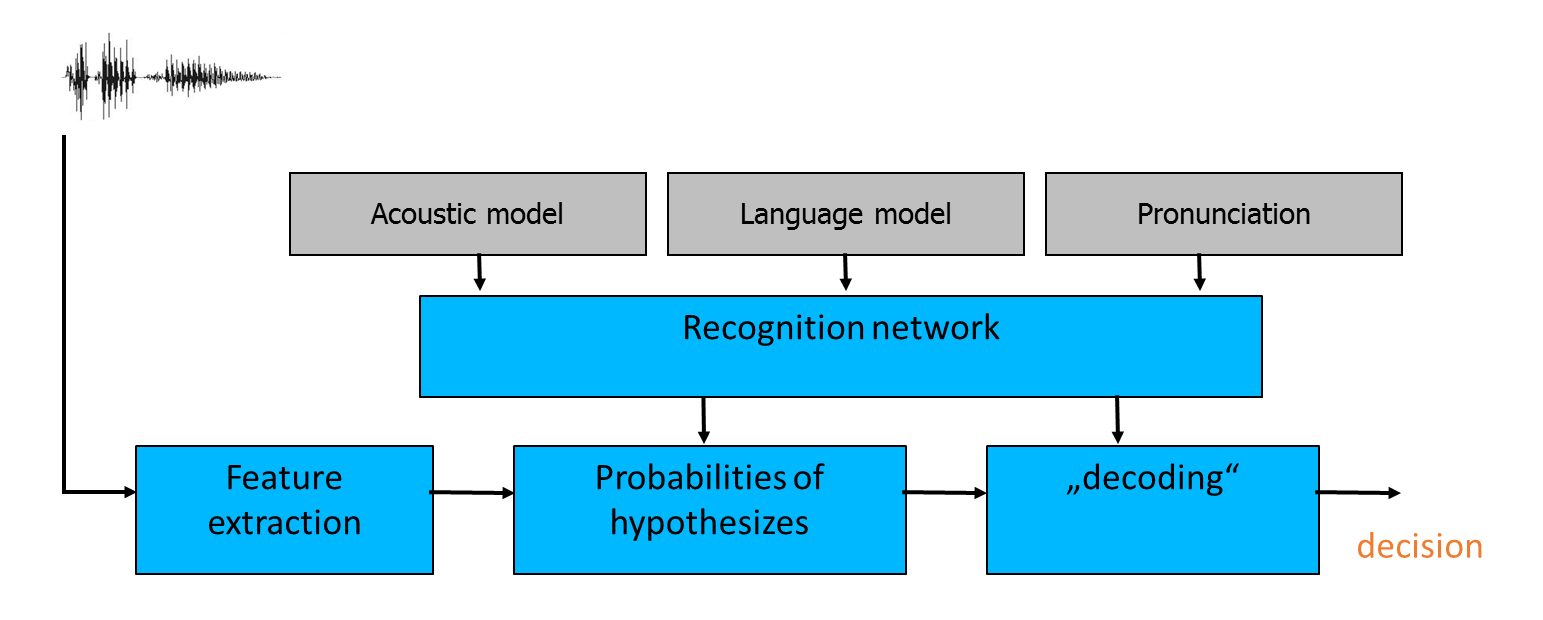
The technology works with both acoustics as well as a dictionary of words, acoustic model, and pronunciation. This makes it dependent on language and dictionary – only a set of words can be transcribed. As input, an audio file or stream is needed, together with the selection of a language model for transcription. The output provides transcription in one of several formats. The technology extracts features out of voice, using acoustic and language models, together with pronunciation; all in a recognition network creates a hypothesis of transcribed words and “decodes” the most probable transcription. Based on the requested output types, one or more transcribed texts are returned with score and time frame.
Application areas
- Maintain high reaction times by routing calls with specific content/topics to human operators
- Search for specific information in large call archives
- Data-mine audio content and index it for search
- Advanced topic/content analysis provides additional value.
Technology overview
- Trained with emphasis on spontaneous telephony conversation
- Based on state-of-the-art techniques for acoustic modeling, including discriminative training and neural network-based features
- Output:
- One-best transcription - i.e., a file with a time-aligned speech transcript (time of word’s start and end)
- Variants for transcriptions – i.e., hypotheses for words at each moment (confusion network) or hypotheses for utterances at each slot (n-best transcription)
- Processing speed – several versions are available: from 8x faster than real-time processing on 1 CPU core (e.g., a standard 8 CPU core server (8 instances of STT) can process 1010 hours of audio in 1 day of computing time (flat load, depending on the technology model))
Here you can find the list of supported languages.
Acoustic models
The acoustic model is created by training on a specific dataset. It includes characteristics of the voices of a set of speakers provided in a training set.
Acoustic models can be created for different languages, such as Czech, English, French, or others, and also for separate dialects – Gulf Arabic, Levant Arabic, etc. From the technology point of view, the difference between various languages is similar to the difference between dialects – every created model will be better suited for speakers with similar speech patterns.
For example, in English, the following acoustic models can be trained:
- US English – to be used with US speakers
- British English – to be used with UK speakers
Language models
The language model consists of a list of words. This is a limitation for the technology because only words from this list can be included in the transcription.
Together with the list of words, n-grams of words are present. N-grams are useful during decoding and making decisions. The technology takes into account word sequences from training data to “decide” which of the possible transcriptions are most accurate.
Language models can differ even for the same acoustic models. This means they may include different words and different weights for n-grams. Using this, users can adjust the language model, focusing on a specific domain to get better results.
Result types
During the process of transcribing speech, there are always several alternatives for a given speech segment. The technology can provide one or more results.
1-best result type provides only the result with the highest score. Speech is returned in segments, each including one word. Each segment provides information about start and end times, the transcribed word, and a score.
n-best result provides several alternatives for sentences or bigger segments of speech with corresponding scores. This can be useful for analytics programs that can process multiple inputs. It is especially useful when speakers do not pronounce words clearly, and the top result might not match the actual words spoken.
Confusion network result type provides similar output to n-best, but segments are returned word by word. The confusion network can be useful for similar purposes as n-best.
Training of new models
To create a new STT model, about 100 hours of annotated speech (not just recordings) is required. The speech source needs to match the intended usage of the created model. Phonexia specializes in telephony speech (landline, GSM, VoIP).
In addition to annotations for the training recordings, additional text data is used to create the language model, making it more robust. The best type of data is similar to the intended use case of the resulting model, typically spontaneous speech. However, as it is difficult to obtain large amounts of such data, other sources are used.
Adaptation
The technology can be adapted at two levels – Acoustic Model or Language Model.
Adapting the Acoustic Model to speakers from a specific region or dialect essentially means creating a new acoustic model. If there is not enough data to train a completely new model, the available new data can be combined with the data used for training the existing model. Based on these datasets, a new, more robust model can be created. However, this training process takes time.
Adapting the Language Model is easier. This can be done when certain words are missing in the language model (such words would never appear in transcription), such as words from a specific business domain, or when undesirable words appear, e.g., informal spellings or offensive words instead of similar-sounding correct words.
The Language Model can be adapted in two ways. First, faster but less precise, by adapting individual words; second, by providing texts corresponding to 20 hours of audio from the target domain containing the desired words. The second option also provides information about the usual contexts in which the words occur.
Since the 5th generation of STT, we have developed a tool that allows customers to customize language models by adding words specific to their domain or use case.
Accuracy
To measure the accuracy of Phonexia Speech to Text, the following points should be considered:
- Reason for accuracy measurement: What is the business value for measuring accuracy? What type of output will be used for the use case in which accuracy is measured? For example, only nouns, verbs, and adjectives might be important for understanding speech context, or all words might matter if the output is intended for human processing.
- Data quality: Every metric requires comparing automatic transcription to a
baseline transcription, usually in the form of annotated data. The quality of
the annotated data is crucial as it impacts the result of the measurement.
Annotation may differ by companies:
- Half-automated annotation – auto-transcription reviewed by human annotators
- Annotation by two independent people
The aim of the annotation can vary – it might be used for training a new model or solely for measuring quality.
- Data processing before measurement: Output data from transcription will
include pure speech transcription, while annotation may contain symbols not
output by the transcription system.
- Numbers: transcription will say "thirteen" instead of "13 - which may appear in the annotation
- Parentheses: transcription says "parentheses" - annotation shows "( )"
- National alphabet characters: transcription uses a limited alphabet, while the annotation may include characters like "ěščřžů,…"
Data in the annotation needs to be processed to include only characters allowed in the transcription to avoid impacting the quality measurement.