Faster than Real Time (FTRT) Metric
The Faster than Real Time (FTRT) metric is developed to define a software performance reference point. We recognize two measurable metrics: Audio-based FTRT and Net Speech-based FTRT. Using these metrics, you can collect "benchmark" data on the real processing speed for the reviewed software, which should be replicated on precisely defined hardware.
By comparing various benchmark results, you can assess the performance of specific software and its components on different hardware configurations. Conversely, using the same metric, you can compare software from different vendors on the same hardware configuration for the same processing task.
Audio-based FTRT
Audio-based FTRT is calculated from the actual audio in its original form, including both spoken speech parts and non-speech signals (such as background noise, technical signals like ringing, DTMF tones, etc.).
This metric is useful for evaluating performance on real audio data entering the audio processing pipeline.
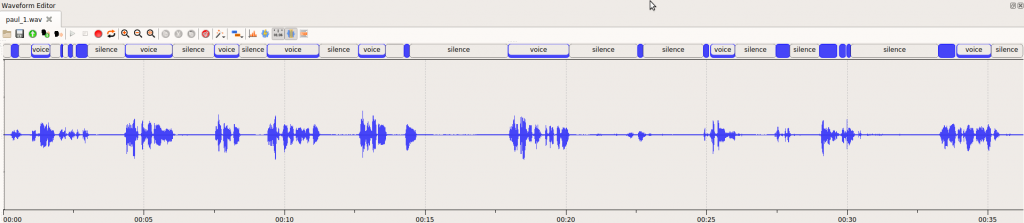
**Regular recording with Voice and Silence segments in waveform
Net Speech-based FTRT
Net Speech-based FTRT is a conservative, purely technical metric. It is calculated using only spoken speech data, with all non-speech parts (silence, noise, DTMF tones, etc.) removed.
This metric is useful for comparing technology performance on different hardware configurations or comparing the performance of similar technologies produced by different vendors.
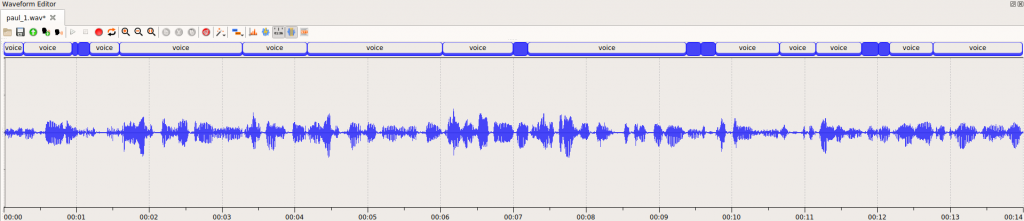
Same recording with silence segments stripped and only speech segments kept in waveform
The calculation formula is very simple and is the same for both use cases:
FTRT = audio_length[s] / processing_time[s]
Example
The original audio length in our example is 36 seconds. After stripping silence, it is reduced to 14 seconds—this means that the original audio contains 38% net speech and 62% silence.
Phonexia speech technologies analyze the entire recording but process only the speech segments for AI processing, meaning the absolute processing time will be nearly the same.
| Task | Processing Time | Hardware |
|---|---|---|
| Creating a voiceprint by Speaker Identification | 0.20 seconds | Intel® Xeon® E5 2860 v4 |
| Creating a voiceprint by Speaker Identification | 0.168 seconds | Intel® Xeon® Platinum 8176 |
Let's calculate:
Intel® Xeon® E5 2860 v4 performance:
FTRT(audio) = 36/0.20 => 180 FTRT
FTRT(net_speech) = 14/0.20 => 70 FTRT
Intel® Xeon® Platinum 8176 performance:
FTRT(audio) = 36/0.168 => 214 FTRT
Conclusion
- FTRT (net_speech) shows that Intel® Xeon® Platinum 8176 computing performance is better by ~17% compared to Intel® Xeon® E5 2860 v4.
- FTRT (audio) demonstrates that the actual hardware and computing power requirements are approximately 62% lower than the traditional approach using FTRT (net_speech) for an audio dataset with a similar ratio of speech to non-speech (silence), as proven by measurement.
Best Practices
-
Use FTRT (audio) when calculating hardware sizing and scaling options, especially for installations designed for mass data processing where each I/O operation is critical. Remember to test real datasets (recordings) for statistical information like the speech-to-non-speech ratio. This approach can significantly assist in budget calculations.
-
Use FTRT (net_speech) when comparing individual CPU performance with a strict academic methodology and an exact reference point.