Arabic Dialects in Phonexia Language Identification and Speech to Text
The Arabic language has one standardized variety and many non-standard varieties (dialects). In this article, our linguistic team explains the differences between Modern Standard Arabic and Arabic dialects in the context of Phonexia Arabic models.
Standard variety: Modern Standard Arabic (MSA)
- All Arabs learn it at school (not from their parents, so it is not their native variety)
- It is the lingua franca (common language) for the Arabic world, similar to English for Europeans. However, Arabs speak it more fluently since they are taught MSA from an early age.
- MSA is more similar to some dialects (e.g., Levantine) but is vastly different from others (e.g., Moroccan Arabic). Therefore, if you speak only MSA, you might understand Levantine slightly but not Moroccan.
Data acquisition
AUDIO (used for LID and STT training): MSA is used in formal speaking situations such as sermons, lectures, news broadcasts, and speeches.
- It is quite difficult/impossible to find recordings of spontaneous phone conversations in MSA.
- Available MSA recordings are usually from broadcasts (microphone) or formal scripted speeches (also microphone).
TEXT (used for STT language model training): MSA is used in all formal writing, such as official correspondence, literature, newspapers, and websites.
- There is no issue accumulating a large amount of text, but it will be more formal and not reflective of spontaneous speech.
Support for MSA in Phonexia products
| Name | LID L4 | STT | Description |
|---|---|---|---|
| Arabic (MSA) | arb | — | Modern Standard Arabic, official language in most countries of the Arab world |
Non-standard varieties: Arabic dialects
- Dialects are native regional varieties in the Arab world.
- They are used in all spontaneous contexts (friends, family) and in more formal environments (work, businesses), meaning dialects are used in all daily life situations, making them more relevant to our customers.
- Depending on the criteria for classifying dialects, there are between 10 and 30 Arabic dialects:
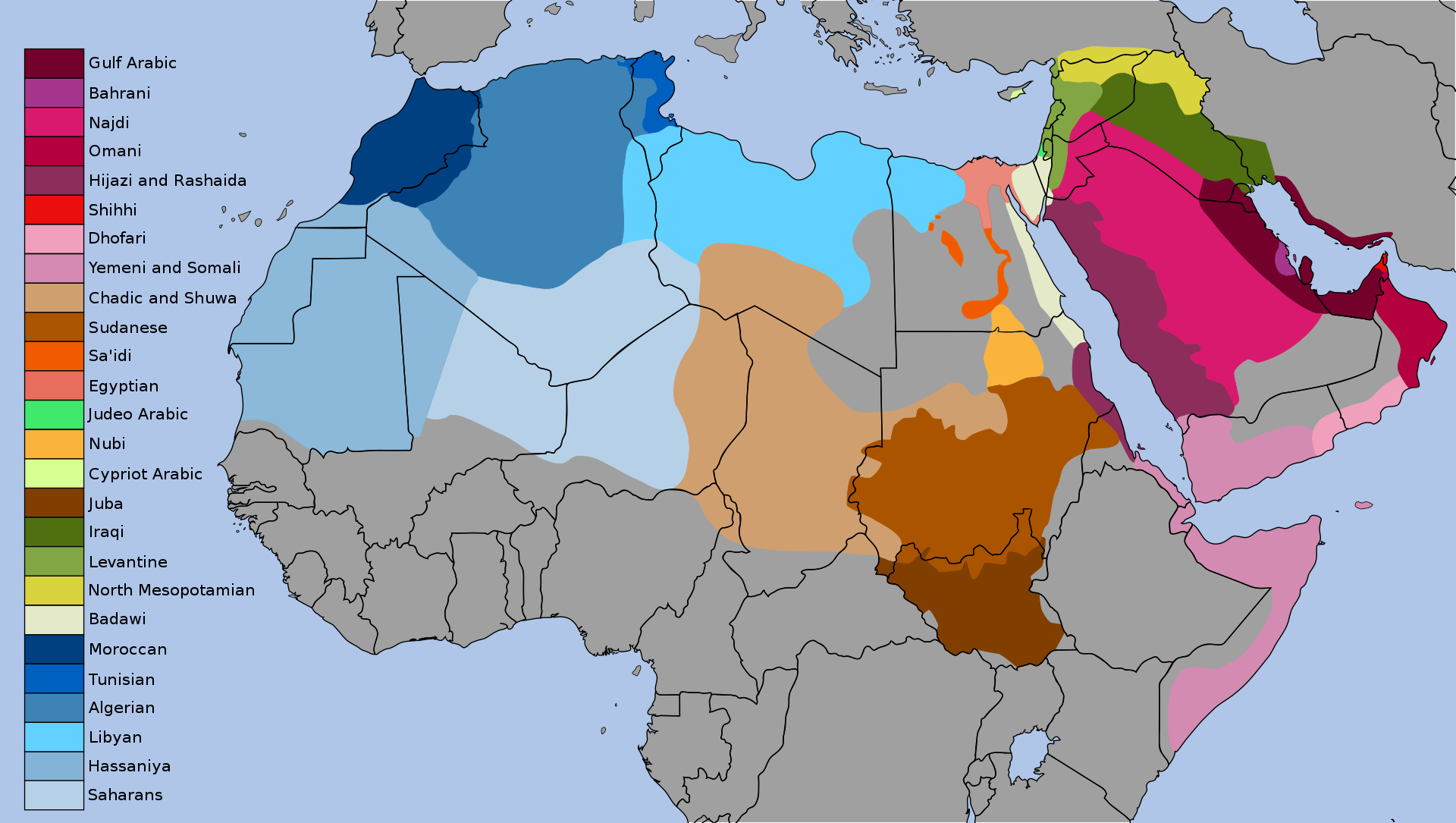
Arabic dialects (image source: Wikipedia)
- There is no standard norm for writing; speakers have two options:
- Use MSA for writing something more formal.
- Use a dialect for more personal communication, like on Facebook, Twitter, or forums.
Data acquisition
AUDIO (used for LID and STT acoustic model training):
- There is no difficulty in collecting spontaneous speech in dialects.
- However, it can be challenging to create annotations for STT training—dialect speakers write words as they hear them, but due to the lack of a standardized writing system, different speakers may write words differently. Therefore, annotations in dialect need to be double-checked and unified.
TEXT (used for STT language model training): Dialects are used for more personal communication on platforms like Facebook, Twitter, and forums.
- There is not much material available, as most written texts are in MSA.
- Facebook, Twitter, and forums can be sources, but they need to be classified, corrected, and unified manually—which is not done at Phonexia.
These are the reasons for the limited out-of-the-box support for Arabic dialects in STT.
Support for Arabic dialects in Phonexia products
| Name | LID L4 | STT | Description |
|---|---|---|---|
| Arabic (Egypt) | ar-EG | — | Arabic variety spoken in Egypt |
| Arabic (Gulf, Kuwait) | ar-KW | AR_KW_6 | Arabic variety as spoken in Kuwait |
| Also spoken in Bahrain, Al Hasa, Qatif, United Arab Emirates, Qatar, Southern Iraq, and Northern Oman | |||
| Arabic (Iraq) | ar-IQ | — | Arabic variety as spoken in Iraq |
| Also spoken in Syria, Turkey, Iran, Kuwait, Jordan, parts of northern and eastern Arabia | |||
| Arabic (Levantine) | ar-XL* | AR_XL_6* | |
AR_XL_5* | Arabic variety spoken in Lebanon, Jordan, Syria, Palestine, Israel, and Turkey | ||
| Arabic (Maghrebi, Morocco) | ar-MA | — | Arabic variety spoken in Morocco, Algeria, Tunisia, Libya, Western Sahara, Mauritania |
There are two distinct varieties of Levantine Arabic, each with a separate
language code—North Levantine (apc) and South Levantine (ajp).
Our models were trained using data from both varieties, so following
RFC 5646, section 2.2.4, we
created a custom language code ar-XL, where XL stands for "cross-Levantine."
To achieve the best STT results, use the model corresponding to the given
dialect. The AR_XL_* model is best suited for Levantine dialect
recordings.
Using the AR_XL_* model for neighboring dialects, such as Iraqi, will result
in significantly lower accuracy, and for dialects like Maghrebi, the results
will likely be completely unusable.