Keyword Spotting Overview
Phonexia Keyword Spotting (KWS) technology enables the identification of specific keywords and key phrases within audio recordings. This tool is designed to extract valuable insights from large volumes of speech data. Users can define the keywords or phrases they are interested in, and the system will detect all instances of these keywords across the recordings. Additionally, this technology facilitates the automatic routing of relevant recordings or calls to designated experts for further analysis.
Typical use cases
Call centers
- Enhance operator and supervisor efficiency by searching for specific calls.
- Detect inappropriate language or expressions used by operators.
- Monitor marketing campaigns through automated script compliance checks.
Mass media and web search engines
- Index and search multimedia content by keyword.
- Route multimedia files and streams based on their content.
Security/defense
- Ensure rapid response times by directing calls with specific content to human operators.
- Search for targeted information within large call archives.
- Trigger immediate alarms (in real-time) when specific events are detected.
Technology
Phonexia Keyword Spotting technology operates purely on acoustic analysis, independent of any language dictionary. This allows for the detection of any words or phrases, including those in foreign languages.
Keyword Spotting utilizes a keyword list containing one or more keywords. Each keyword can have an optional threshold value and/or different pronunciation variants.
While there is no limit to the number of keywords or pronunciations that can be used, performance may decrease with larger keyword lists, particularly when pronunciations are not explicitly defined. In such cases, the technology generates pronunciations internally, which can lead to delays, especially if the list contains many undefined pronunciations. To maintain optimal performance, it is recommended to use a maximum of approximately 200 keywords unless pronunciations are predefined. If all keywords have predefined pronunciations, even lists with thousands of keywords do not impact performance.
The technology processes audio recordings and returns a list of detected keywords, each with an associated score and confidence level. The score represents the probability that a keyword was spoken within a specific time frame.

Keywords
Keywords are not dependent on any dictionary. This flexibility allows you to define specific, foreign, or even nonexistent words, such as product names.
However, keywords must be composed of allowed graphemes (symbols) from a supported list. This list of supported graphemes can be easily obtained from the Speech Engine or through Command Line implementation.
If Keyword Spotting rejects a keyword and returns an error, verify that the keyword contains only allowed graphemes.
Pronunciations
Keywords can be defined with or without an explicit pronunciation. If a pronunciation is not provided, the system will create a default pronunciation internally. The default pronunciation is either sourced from a dictionary (if the keyword exists in the dictionary) or generated automatically using a grapheme-to-phoneme mechanism for keywords not found in the dictionary.
Pronunciations generated by the grapheme-to-phoneme mechanism are assigned a
probability value, indicating the system's confidence in the generated
pronunciation. This value is expressed as a logarithm of probability within the
range from a negative value up to 0.
It is important to note that the actual pronunciation of keywords in recordings may differ from what Keyword Spotting anticipates. This is especially true for product or brand names, domain-specific terms, misspelled words, or incorrectly pronounced foreign words. Therefore, it is highly recommended to explicitly specify the pronunciation (or multiple pronunciation variants) for keywords to ensure accurate detection.
The simplest approach to defining a pronunciation is to use the automatically generated pronunciation as a starting point and modify it as needed.
Alternatively, a Phoneme Recognizer (PHNREC) can be utilized to derive (or "transcribe") the pronunciation directly from actual audio recordings.
Phoneme recognizer
The Phoneme Recognizer (PHNREC) provides the phoneme transcription of a specified audio recording or a segment of it. This feature can be used to determine the actual pronunciation of a keyword or phrase as spoken in the audio recording. The extracted pronunciation can then be included in a keyword list for Keyword Spotting.
To improve accuracy, it is advisable to limit the start and end times of the Phoneme Recognizer's transcription to the specific time frame where the word or phrase of interest occurs.
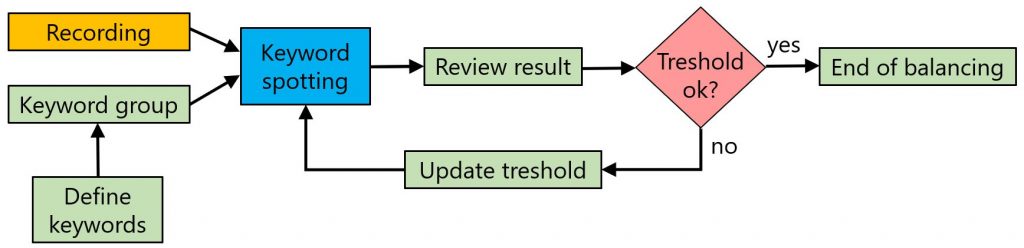
Thresholds
A threshold is a numeric value within the range of 0 to 1 that limits the output results. Only keywords with confidence scores exceeding the threshold are returned.
The command line implementation of Keyword Spotting supports a global, list-wide threshold as well as optional thresholds for individual keywords. If a threshold is set at the keyword level, it overrides the global threshold.
The Speech Engine (SPE) supports thresholds only at the keyword level.
Setting the appropriate threshold is crucial for obtaining relevant results and significantly enhances the accuracy of the technology. However, determining the correct threshold can be challenging because it is based on confidence, which is derived from the raw score using a sigmoid function.
For more detailed guidance, please refer to the Keyword Spotting results explained article.
Keyword list example
Below is an example of a keyword list in JSON format for use with the Speech Engine:
- The
contractkeyword is enabled (i.e., it will be included in the search), does not specify a confidence threshold (i.e., a default value of0will be used, meaning all detected occurrences will be reported), and does not explicitly specify any pronunciation (i.e., a default pronunciation generated internally using the grapheme-to-phoneme mechanism will be used). - The
iPhonekeyword is disabled (i.e., it will not be included in the search), specifies a confidence threshold value of0.6(i.e., if the keyword were enabled, only occurrences with a confidence score equal to or higher than the threshold would be reported), and does not explicitly specify any pronunciation (i.e., an internally generated default pronunciation would be used). - The
MITkeyword is enabled, specifies a confidence threshold value of0.4, and includes two pronunciations, one of which is enabled and the other disabled (i.e., only the enabled pronunciation will be used in the search).
{
"keywords": [
{
"name": "contract",
"enabled": true
},
{
"name": "iPhone",
"enabled": false,
"threshold": 0.6
},
{
"name": "MIT",
"enabled": true,
"threshold": 0.4,
"pronunciations": [
{
"phonemes": "eh m ay t iy",
"enabled": true
},
{
"phonemes": "m ih t",
"enabled": false
}
]
}
]
}