Speaker Diarization
The Speaker Diarization technology labels segments of the same voice(s) in a mono recording based on individual speakers' voices. It is independent of language, domain, and channel. The output is a list of time segments with speaker labels. Besides speaker segmentation, it can also detect technical signals and silence.
Typical use cases
- Preprocessing audio for other speech recognition technologies.
- Labeling parts of an utterance according to speakers.
- Splitting mono phone call recordings into multiple channels.
- Identifying how many speakers are present in the recording.
How does it work?
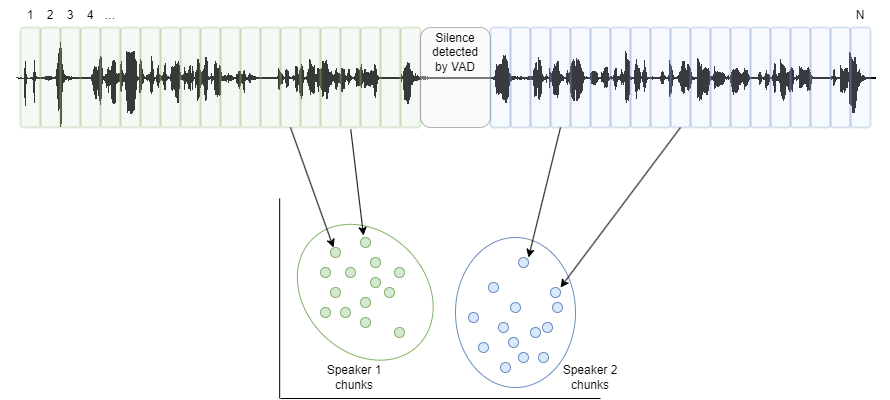
Speaker Diarization is based on the Speaker Identification technology. It consists of the following steps:
- Filtering out segments of silence and technical signals (Voice Activity Detection).
- Splitting the voice segments into small chunks.
- Creating a voiceprint for each chunk.
- Computing distance between the voiceprints of all the chunks.
- Creating groups of chunks according to distance using a clustering algorithm.
- Completing and smoothing out the final segmentation using a variational Bayes algorithm.
See the following image for better understanding:
Clustering algorithm
An important step in Speaker Diarization is voiceprint clustering. There are many algorithms for clustering, each with its own advantages and disadvantages. In the Phonexia Speaker Diarization XL5 model, we use the Agglomerative Hierarchical Clustering algorithm. This is a bottom-up approach to clustering data points. It starts with each data point as its own cluster and iteratively merges clusters based on a similarity metric until all data points belong to a single cluster or a stopping criterion is met.
Variation Bayes algorithm
The Variational Bayes (VB) algorithm for Speaker Diarization is a probabilistic method used to partition an audio recording into segments, each associated with a single speaker. Based on Bayesian inference, it seeks to estimate the posterior distribution over speaker identities for each time frame in the audio. The Variational Bayes algorithm offers a flexible and robust framework for Speaker Diarization by combining probabilistic modeling with Bayesian inference techniques, allowing for accurate segmentation of audio recordings with multiple speakers.
Scoring
The most common metric for evaluating the performance of Speaker Diarization systems is Diarization Error Rate (DER). It measures the overall error rate by calculating three types of errors:
- Missed speech segments.
- False alarms.
- Speaker confusion errors.
Missed Speech Segments: These are segments of speech in the reference (ground truth) segmentation that are not correctly detected by the diarization system. In other words, if a speaker's speech segment in the reference is not assigned to any speaker, it results in a missed speech segment error.
False Alarms: These are segments of speech detected by the diarization system that do not correspond to any speaker in the reference segmentation. In other words, if the diarization system falsely assigns speech to a speaker where there should be none according to the reference, it results in a false alarm error.
Speaker Confusion Errors: These occur when the diarization system incorrectly assigns speech segments to the wrong speaker. For example, if a speech segment from one speaker is incorrectly labeled as belonging to another speaker by the diarization system, it results in a speaker confusion error.
The diarization Error Rate (DER) is then calculated as the sum of these three error types, normalized by the total duration of the reference segmentation:
A lower DER indicates better performance, as it reflects fewer errors in the diarization output with respect to the reference segmentation.
The DER metric is not the only metric used to measure diarization accuracy. The other common metric is the Jaccard Error Rate (JER) which is based on the Jaccard similarity index.
Number of speakers
By default, Phonexia Diarization automatically detects the number of speakers.
However, the system's accuracy can be enhanced by inputting the actual number of
speakers. For example, if users know that the number of speakers in the input
recording is not more than N or the number is exactly N, they can specify
this with the max_speakers or total_speakers input parameters.
FAQ
Why does the diarization system detect more speakers than there actually are?
This can happen for several reasons. Here are the most common ones:
- The recording contains segments in which two or more speakers speak at the same time (crosstalks).
- The audio channel of a single speaker changes over time.
If you know the exact number of speakers in the recording, you can specify this with the total_speakers input parameter. If you don't know the exact number of speakers but you know the maximum possible number of speakers, you can specify this by using the max_speakers parameter.
What is the typical DER for state-of-the-art diarization systems?
The accuracy of current systems is typically less than 10% DER, but it depends on many factors such as the number of speakers and the number of crosstalks.
What is the processing speed of the Speaker Diarization technology?
The processing speed on modern CPUs is approximately 20 times faster than real time, meaning that 20 seconds of audio can be processed in just 1 second. However, this speed can vary depending on the amount of speech present in the audio.