Release Notes
Speech Platform release 3.61
Main feature of this release is removing the historical specifics of "embedded Speech Engine" mode in Phonexia Browser, which could confuse our users:
- Separate SPE configuration files (
phxspe.browser.propertiesandtechnologies.json) - Separate SPE database file (
phxserver.sqlite) placed in SPE "home" directory - SPE technologies configuration available only for the "embedded SPE"
Since this release, technologies configuration is now available also for "remote SPE" and the standard SPE configuration files are always used.
New features and fixes
Speech Engine: General
- New parameter
show_allforGET /technologiesendpoint for listing all technologies available on the server, including technologies not currently running (calling the endpoint without this parameter lists only currently running technologies) - New
POST /technologiesendpoint for setting new technologies configuration - New
/server/shutdownand/server/restartendpoints for SPE shutdown and restart (SPE restart is needed to load new configuration)
Speech Engine: Speaker Identification (SID4)
- Added possibility to set score thresholds when calling
GET/POST /technologies/speakerid4.
When using large speaker groups (thousands or more speakers), setting score thresholds can significantly reduce the number of returned results, i.e. reduce the size of the API response.
Smaller response is transferred faster and parsed faster, thus may dramatically speed up the entire process.
Speech Engine: Speech to Text (STT)
- Improved behavior of voice detection in realtime stream transcription.
In fact, we have implemented the internal voice activity detection from 5th STT generation, which behaves much better on realtime stream audio (this change does not affect files processing, only realtime streams).
Speech Engine: other technologies
- Fixed long-standing Diarization bug when results for multichannel audio returned timestamps greater than the length of the audio
- Fixed Time Analysis Extraction bug when total audio length in processing result was incorrect
- Also fixed Time Analysis Extraction bug when crosstalks were returned in processing result even for channels which did not contain any speech
Phonexia Browser
- Changed dialog for adding server to allow adding both "remote" and "embedded" SPE
- It is now possible to restart or shutdown the SPE using server context menu commands
- Added new dialog for technologies configuration, accessible from server context menu in Server Administration
- It is now possible to configure also realtime stream technologies (however, note that Browser itself does not support realtime streams)
- Diarization results of multichannel recordings are now displayed in the Results pane separately for each channel
- Transcription can now be displayed more user-friendly by sentences starting with capital letter and ending with full stop. This can be turned on in Settings / General.
- Updated icons for technologies to match the other Phonexia visuals
For a complete list of the changes in SW, see these changelogs:
- SPE →
CHANGELOG.txtincluded in the distribution, or Releases and Changelogs (SPE) - BROWSER →
CHANGELOG.txtincluded in the distribution, or Releases and Changelogs (Browser)
Deprecated features
The legacy 3rd generation Speaker Identification technology – i.e. all endpoints
under /technologies/speakerid – was deprecated and will be removed in one of
the future releases.
Previous Releases
Speech Platform release 3.60
Here is a summary of most important new features and fixes since last Public Release 3.55.
New features and fixes
Speech Engine: general
- Reduced RAM consumption (since 3.58.0)RAM consumption can be up to several gigabytes lower, depending on technologies configuration and processed audio. This is mainly visible in Speech To Text when processing many audios or longer audios (or both). The effect may be less visible in other technologies.
- Fixed issues with non-ASCII / Unicode file names on Windows under certain circumstances (since 3.59.0)
- Fixed issues with starting technologies in Speech Engine on Windows from UNC path (since 3.58.0)
Speech Engine: Speech To Text (STT) and Keyword Spotting (KWS)
- New and updated STT and KWS languages
- Bengali model BN_6 added in 3.55.1 with word accuracy (WAcc) up to 55 %
- Kazakh model KK_KZ_6 added in 3.55.1 with word accuracy (WAcc) up to 77 %
- Ukrainian model UK_UA_6 added in 3.58.0 with word accuracy (WAcc) up to 85 %
- Serbian model SR_RS_6 added in 3.58.0 with word accuracy (WAcc) up to 84 %
- Russian models RU_RU_6 updated in 3.59.0 with word accuracy (WAcc) up to 94 %
- Hungarian model HU_HU_6 added in 3.60.0 with word accuracy (WAcc) up to 81 %
- Phoneme Recognition technology is now included with Speech To Text
This should help users with defining pronunciations in preferred phrases, when adding words to language model, or when creating customized model - Added grammar rules for words to numbers conversion in 3.59.0.
- Pre-defined rules for English, Spanish and Polish were added. For other languages we provide empty definitions which can be edited by users.
Speech Engine: Speaker Identification (SID4)
- New "floating window" feature for realtime stream processing (since 3.60.0)
This newfloating_windowparameter allows to identify speaker or extract voiceprint from only last X seconds (default 5) of speech in the realtime stream... as opposed to using speech from entire stream audio without using this parameter.
Speech Engine: Other technologies
- New Gender Identification (GID) model XL5 (since 3.56.0)
This enables GID to use voiceprints created by the brand new Speaker Identification 4 model XL5 - New Age Estimation (AGE) models XL4 and XL5 (since 3.57.0)
This enables AGE to use voiceprints created by the Speaker Identification 4 model XL4 and XL5 - New Voice Activity Detection (VAD) model SID4_XL5 (since 3.58.0)
The SID4_XL5 model uses exactly the same parameters as internal VAD built-in in Speaker Identification 4 (SID4), giving exactly the same results (amount of speech, speech segments boundaries).
This model should help preventing rare situations when analyzing a recording using VAD GENERIC_3 model detected just enough speech for a voiceprint, but actual voiceprint creation failed due to not enough speech being detected in the audio. - When estimating PESQ score using Speech Quality Estimation (SQE), non-speech
parts of audio are ignored (since 3.59.0)
This improvement helps getting more realistic PESQ scores with audio containing significant amount e.g. silence or ringtones as these get filtered out by internal voice activity detection.
Phonexia Browser
- Transcriptions can be saved to a text file, either using the Save icon directly from the transcription widget, or from the Results pane using the context menu command (since 3.60.0)
- It is now possible to set Minimum speech length to less than 7 seconds in Settings dialog (since 3.58.0)
- Fixed issues with non-ASCII / Unicode file names on Windows under certain circumstances (since 3.59.0)
- SPE Output pane is now displayed by default and gets focused when SPE is started in the background by Browser (since 3.59.0)
- More detailed debug output is now configurable in Settings dialog and is
enabled by default (since 3.59.0)
This should help users with tracking down the causes of various issues. - The Enable all and Disable all icons in technologies configuration section of Settings dialog are updated to better express their meaning
For a complete list of the changes in SW, see these changelogs:
- SPE →
CHANGELOG.txtincluded in the distribution, or Releases and Changelogs (SPE) - BROWSER →
CHANGELOG.txtincluded in the distribution, or Releases and Changelogs (Browser)
Speech Platform public release Fall 2022 (SPE v3.55)
Welcome to the page introducing the fall 2022 public release of the Phonexia Speech Platform. We have improved and released mainly Phonexia Speech Engine v3.55 (SPE, REST API).
Due to internal changes, the 3.55 release is not compatible with previous
technology configuration files (*.bs). Therefore, when updating to version
3.55, it's necessary to get current version of all technologies and models
used in your deployment from Phonexia.
In other words, copying technologies/models from previous SPE installation won't
work and you would see various sorts of error messages when initializing the
technologies.
If you are using customized STT model created by LMC, you need to
re-create the customized model
using current STT version and the original list of added words.
New Features and Fixes
Speech Engine: The 5th generation of Speaker Identification (SID)
We are eager to introduce a new 5th generation model XL5 of our Speaker Identification. Its main highlights are:
- Increased accuracy by 1 p.p. (33 % lower EER) over XL4 model, especially on 16 kHz audio (VoLTE)
- Same or faster processing speed than XL4 model
- Optional backward voiceprint compatibility with XL4 model (compatibility must be explicitly enabled)
Speech Engine: Speech to Text (STT)
We have several exciting new features relevant to STT and KWS technologies:
- Czech (Czech Republic) language model updated (tech. model name:
CS_CZ_6):
We added new words to the language model, so recent frequent words like “COVID” are correctly transcribed. - Slovak (Slovakia) language model updated (tech. model name:
SK_SK_6):
We added new words to the language model, so recent frequent words like “COVID” are correctly transcribed. - German (Germany) new-generation model DE_DE_6:
It is an upgrade of previous 4th generation (DE_4) of STT/KWS.
STT word accuracy (WAcc) is increased up to 90 % (up to 21.8 p.p. improvement). - Russian (Russia) new-generation RU_RU_6 model:
It is an upgrade of previous 5th generation (RU_RU_5) of STT/KWS.
STT word accuracy (WAcc) is increased up to 90,8 % (up to 7.1 p.p. improvement). - Polish (Poland) new-generation PL_PL_6 model:
It is an upgrade of previous 5th generation (PL_PL_5) of STT/KWS.
STT word accuracy (WAcc) is increased up to 85.3 % (up to 18.7 p.p. improvement). - Italian (Italy) new-generation IT_IT_6 model:
It is an upgrade of previous 3rd generation (IT_IT_3) of STT/KWS.
STT word accuracy (WAcc) is increased up to 78.2 % (up to 20 p.p. improvement). - Dutch (Netherlands and Belgium) new-generation NL_6 model:
It is an upgrade of previous 5th generation (NL_NL_5) of STT/KWS.
STT word accuracy (WAcc) is increased up to 86.1 % (up to 24 p.p. improvement). - Arabic (Gulf, Kuwait) new-generation AR_KW_6 model:
It is an upgrade of previous 4th generation (AR_KW_4) of STT/KWS.
STT word accuracy (WAcc) is increased up to 57.9 % (up to 8.8 p.p. improvement). - Georgian (Georgia) brand-new model KA_GE_6 released:
It is a completely new model in the STT/KWS family.
STT word accuracy (WAcc) is up to 66.4 %. - Chinese Mandarin (China) brand-new model ZH_CN_6 released:
It is a completely new model in STT/KWS family.
STT word accuracy (WAcc) is up to 93.1 %.
Speech Engine: Other technologies
- Speaker Diarization (DIAR XL4) - We solved the issue of an extreme (exponential) processing time increase on long recordings (the processing time increase is now linear).
- Automatic configuration of some Speech Engine (SPE) settings values - SPE is now more user-friendly as it can configure its workers settings automatically based on detected hardware and technologies configuration.
- Speech Engine (SPE) now distributed also via DockerHub - simply search for phonexia/spe.
- The CMD/CLI interface now part of Speech Engine (SPE) package -
phxcmd[.exe]binary is now included in SPE’s folder, so technologies can be easily tested using command line interface.
Phonexia BROWSER Update
We finished small but important improvements:
- The Age column in Results pane now shows the numeric results instead of age groups; column name changed to Age (±10 years) to emphasize the results tolerance
- Added the Keyword Spotting highest confidence column in Results pane,
showing the highest confidence value of all detected keywords in a recording
(allowing to judge the relevance of the detection directly in the Results
pane, without opening the recording)
- Added corresponding Minimum confidence to display setting for Keyword Spotting, which allows to set the threshold for KWS results being displayed in the Results pane.
CMD/CLI Variant to Test Technologies
We re-implemented our command-line interfaces and joined them to one binary
called phxcmd[.exe]. For compatibility with the previous versions, we also
distribute scripts that replace old binaries.
Deprecated Features
In accordance with our Phonexia Product Support Lifecycle Policy and the release of our new technology models, we announce the following features to be deprecated and end of life:
| TECHNOLOGY | DEPRECATED MODEL | STILL SUPPORTED LAST (PREVIOUS) MODEL |
|---|---|---|
| STT/KWS | AR_KW_4 FA_IR_4 IT_IT_3 NL_NL_4 PL_PL_4 RU_RU_4 RU_RU_FIN4 ZH1 | AR_KW_6 FA_6 IT_IT_6 PL_PL_6 (PL_PL_5) RU_RU_6 (RU_RU_5) RU_RU_6 (RU_RU_5) ZH_CN_6 |
| SID | L3 XL3 | XL5(L4) XL5(XL4) |
Deprecated means that the model is still available in the latest release of the Speech Engine (SPE v3.55) but will NOT be released in future SPE versions.
Removed Features
Dropped support for Windows 7 / Windows Server 2008 R2 and older.
We removed the following features as it was announced earlier to be deprecated.
| TECHNOLOGY | DEPRECATED MODEL | STILL SUPPORTED LAST (PREVIOUS) MODEL |
|---|---|---|
| SID | S2 L2 | XL5(L4) XL5(XL4) |
Known Issues
There are no significant issues that we are aware of at the moment. As we are continuously working on the Speech Platform improvements, please help us by reporting any potential issues (see the “Sources and How to Get Help” section below).
Future Product Release Plan
For the next public release, we plan:
- a brand-new model to be released for the Bengali language (both STT & KWS technology, the expected model name is BN_6),
- a brand-new model to be released for the Kazakh language (both STT & KWS technology, the expected model name is KK_6).
Sources and How to Get Help
How to get help / Support updated - We updated the ticketing system for our partners/customers for easy bug reporting.
Partner Portal updated - We updated the knowledge base information for you. You are more than welcome to browse through our knowledge base.
For a complete list of the changes in SW, see these changelogs:
- SPE →
CHANGELOG.txtincluded in the distribution or on Releases and Changelogs (SPE) - BROWSER →
CHANGELOG.txtincluded in the distribution or on Releases and Changelogs (Browser)
Speech Platform public release Spring 2022 (SPE v3.50)
Speech Platform public release Spring 2022 (SPE v3.50)
Hello, and welcome to the page introducing the Spring 2022 release of Phonexia Speech Platform. We improved and released mainly Phonexia Speech Engine v3.50 (SPE, REST API).
Major Changes: New Features and Fixes
Speech Engine: Speech to Text (STT)
We have several exciting new features relevant to STT and KWS technologies. Both technologies are part of the Speech Engine (SPE) component:
- Spanish (General) Model Released (Tech. Model Name: ES_6)
It is an upgrade of the existing STT/KWS language (ES_ES_5) to the 6th generation (ES_6). It provides an increased STT word accuracy (WAcc) of up to 95.2 % (an absolute improvement of 27.6 percentage points—model ES_6 vs. ES_ES_5), leading to more precise search results in audio content. - Slovak (Slovakia) Model Released (Tech. Model Name: SK_SK_6)
It is an upgrade of the existing STT/KWS language (SK_SK_5) to the 6th generation (SK_SK_6). It provides an increased STT word accuracy (WAcc) of up to 88.3 % (an absolute improvement of 11.4 percentage points—model SK_SK_6 vs. SK_SK_5), leading to more precise search results in audio content. - Turkish (Turkey) Model Released (Tech. Model Name: TR_TR_6)
It is an upgrade of the existing STT/KWS language (TR_1) to the 6th generation (TR_TR_6). It improves word accuracy (WAcc) by 9.8 percentage points (model TR_TR_6 vs. TR_1), leading to more precise search results in audio content. - Farsi (Iran and Afghanistan) Model Released (Tech. Model Name: FA_6)
It is an upgrade of the existing STT/KWS language (FA_IR4) to the 6th generation (FA_6). It improves word accuracy (WAcc) by 25 percentage points (model FA_6 vs. FA_IR4), leading to more precise search results in audio content. - New Decoder and VAD Configuration in STT Technology Models
Thanks to a new decoder and VAD components added to our STT, the transcription accuracy (WAcc) has improved on average by 2 percentage points (compared absolutely to our original 6th generation models). The update was applied to all technology models (languages) of the 6th generation of STT and KWS. - Improved Preferred Phrases in STT (All 6th Generation Technology Models)
- Custom words (such as names, slang expressions, etc.) can now be used in Preferred Phrases.
- Single words can now be preferred without any limitations (until now, only single standalone words were allowed to be preferred).
- Classes in Preferred Phrases (the CS_CZ_6 Model Only)
Classes can now be included in Preferred Phrases as a substitute for a group of words (for example, preferring the generic phrase ‘my name is “first_name”’ instead of a list of specific phrases such as ‘my name is Paul’, 'my name is John', etc.).
Speech Engine: Other technologies
- VAD Update (the GENERIC_3 Technology Model From v3.0.0 to v3.0.2)
The VAD GENERIC_3 model was retrained and updated (to v3.0.2). It should now be slightly more robust on various telephony data. Users will benefit from a more precise segmentation of the speech and non-speech parts contained in an audio file. - Important Memory Leak Fix in STT
We applied an important fix to a memory leak that caused slower processing in all STT technology models. We recommend partners take advantage of this STT fix by updating to SPE v3.50. - DB Engine Changed From MySQL to MariaDB
Due to the end of life of MySQL 5.x (supported by SPE so far) and incompatibility of its successor MySQL 8.x, we switched the support of an alternative SPE caching database from MySQL to MariaDB. You can get more info about the SPE caching database in the 'Understand SPE database' article.
Deprecated Features
Deprecated / Removed Technical Models
In accordance with our Phonexia Product Support Lifecycle Policy and the release of our new technology models, we announce the end of life for the following old models:
| TECHNOLOGY | DEPRECATED MODEL | STILL SUPPORTED LAST (PREVIOUS) MODEL |
|---|---|---|
| AGE | L, S | L4 (XL3, L3) |
| DIAR | O | XL4 (S,L) |
| GID | GENERIC | XL4, L4 (XL3) |
| LID | L, S (*) | L4(XL3, L3) |
| STT | FA_IR_4 TR_1 ZH_1 | FA_6 TR_TR_6 To Be Announced |
| KWS | FA_IR_4 TR_TR_3 ZH_1 | FA_6 TR_TR_6 To Be Announced |
Deprecated means that the model is still available in the latest release of Speech Engine (SPE v3.50) but will NOT be released in the future SPE versions. (*) Both models were removed and will not be released in SPE v3.50.
Deprecated / Removed Command Line Interface Parameters
Several command line parameters seem not to be used by our partners and appear to be obsolete. Therefore, in accordance with our Phonexia Product Support Lifecycle Policy, we announce the end of life for the following parameters:
| CLI/CMD | PARAMETERS | NOTE |
|---|---|---|
LID Command Line “lid lid.exe” | -active-langs str1,str2… | Deprecated |
STT Command Line “stt stt.exe” | -auto-scan-dir -move-input -no-locks -local-compliance str1,… -net-compliance str1,… -modif-delay num [3.5s] -stable-att-int num [3.5s] -cn-max-words-per-slot num [0] -cn-min-word-prob num [-70] | Removed |
VAD Command Line “vad vad.exe” | -nonspeech-lab -save-log -log-suffix str [log] | Deprecated |
The End of Life for Several Applications
Several applications have not proved their maturity on the market and have not been used by our partners. Therefore, we announce the end of life for the following applications:
| APP | FUNCTIONALITY | NOTE |
|---|---|---|
| Lobsper | An example of a simple load-balancing app, written in JAVA, on top of SPE. | Removed |
| Workflow | An example of a workflow (pipeline) processing app, written in JAVA, on top of SPE. -stable-att-int num [3.5s] -cn-max-words-per-slot num [0] -cn-min-word-prob num [-70] | Removed |
| REST Server | An old REST server (from v2.x.x to v3.2.x, the SPE predecessor) | Removed |
| JAVA Wrapper | JAVA wrapper on top of the C++ API | Removed |
Known Issues
There are no significant issues that we are aware of at the moment. As we are continuously working on the Speech Platform improvements, please help us by reporting any potential issues (see the “Sources and How to Get Help” section below).
Future Product Release Plan
For the next public release, we plan to:
- Upgrade the Polish model (STT / KWS technologies, the expected model name is PL_PL_6) – an improved accuracy is expected.
- Upgrade the Arabic Gulf model (STT / KWS technologies, the expected model name is AR_KW_6) – an improved accuracy is expected.
- Furthermore, we work on additional STT languages, KWS upgrades, and other technologies based on the requests from our partners and customers.
We also work hard on other products:
- Phonexia Voice Verify - a voice verification solution for contact centers to improve the security layer and customer experience.
- Phonexia Orbis - an on-premises software solution that enables the rapid investigation of audio recordings.
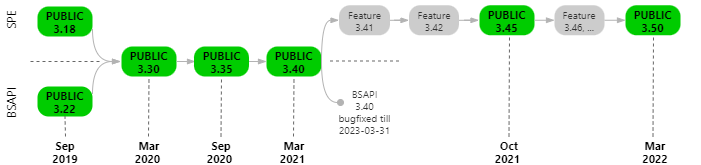
The next release of the Speech Platform Fall 2022 Public Release (the Speech Engine v3.55 and Phonexia Browser v3.55 components) is planned for 30.09. 2022. The diagram below shows the release plan.
Speech Platform public release Fall 2021 (SPE v3.45)
Let us introduce you the Fall 2021 release of Phonexia Speech Platform. We released two components:
- Phonexia Speech Engine v3.45 (SPE 3.45.0 released 2021-10-06) - the encapsulation of speech technologies (REST API)
- Phonexia Browser v3.45 (BROWSER 3.45.0 released 2021-10-08) - the client application on top of SPE (for technologies evaluation)
This page summarizes major changes, bug fixes, and known bugs. We also announce important future plans and the end of life here.
Major Changes: New Features and Fixes
Speech Engine: Speech to Text (STT)
We have several very interesting new features relevant to STT and KWS technologies. Both technologies are part of the Speech Engine (SPE) component:
- English (United States) model (tech.model name: EN_US_6) released
It is the upgrade of the existing STT/KWS language (EN_US_5) to the 6th generation (EN_US_6). It brings increased accuracy 8 % (WAcc, absolute; model EN_US_6 vs. EN_US_5) of the STT that will lead to more precise search results in audio content. - Vietnamese (as spoken in Vietnam) model (tech.model name: VI_VN_6)
released
We add this to languages supported by STT/KWS. Partners/Customers can transcribe Vietnamese audio or enhance some search-in-audio applications. Again, it is the 6th generation we use in automatic speech recognition technologies (i.e., STT, KWS, PHNREC) that will lead to more precise search results in audio content. - Improved preferred phrases in STT- only in tech. model CS_CZ_6 (Czech)
Custom words (not present in the baseline STT model - such as names, slang expressions, etc.) can now be used in preferred phrases. On top of that, this feature can replace the LMC functionality (add custom words dynamically with each transcription attempt with no permanent STT models created). - Improved transcription accuracy in the 6th generation of STT - only in
tech. model CS_CZ_6 (Czech) and model EN_US_6 (English)
Transcription accuracy was improved (thanks to the remastering of several internal components of STT) by more than 2% WER (absolute) on average compared to the original 6th generation model (SPE 3.40.5). An additional benefit is an improved transcription accuracy of the most important information (such as names and addresses). Improvements will be implemented into other 6th generation models/languages soon. - Language Model Customization (LMC) functionality added to SPE (production
level BETA)
LMC is now a native part of the Speech Engine.
Speech Engine: Other technologies
- XL4 technology model added to GenderID
It brings compatibility with SID4_XL4. It saves the processing time significantly in the integration, where the voiceprint is extracted (resources consuming) from audio only once and sent for comparison (fast) to both SID4_XL4 and GID_XL4. - VAD has been upgraded to a new generation (tech. model GENERIC_3)
The model (GENERIC_3) was released for standalone Voice Activity Detection (VAD as part of SPE). It brings higher accuracy in such a fundamental task to recognize speech and non-speech (silence, ringing, etc.) correctly. Using this new generation in built-in VAD in STT CS_CZ_6 (Czech language), we see increased accuracy (WAcc) by approx. 2% absolute. The implementation into other tech. models of STT (i.e., languages) will follow. It does not influence the *ID technologies. - SQE: Added Perceptual Evaluation of Speech Quality (PESQ) score
estimation
The PESQ estimation was added as another available metric of SQE. PESQ is a standard way of expressing speech quality as perceived by human beings. - SQE: Real-time processing
A new technology model SQE_STREAM was added for real-time quality estimation on streams. - Added Speaker Clustering endpoint for SID4 (SURPRISE of this release)
Allows to compare a set of voiceprints and receive clusters of those. It will bring another level of effectiveness in the task of finding similar speakers. This functionality is available only for SID4 technology (tech. model XL4 (recommended default) or L4 (faster but less precise than XL4)).
Speech Engine: Generic functionalities
- Custom request ID can be specified in the HTTP header
X-Request-ID
Useful for tracking down issues during application development - Possibility to set a source port for an output stream
Useful when symmetric RTP communication is needed - Added
/docendpoint for serving REST API documentation in HTML format
Get API documentation for your particular SPE version remotely, without physical access to SPE installation files
Phonexia Browser updates
We provide Phonexia Browser (a component of Speech Platform) for the basic evaluation of speech technologies. This is to help with the first use of our SPE component.
- LID language models and language packs management in Browser
It allows users to e.g. easily customize the set of languages in LID language packs. Customers will benefit from increased precision of results by lowering the false positive scores on customer data. Available for all LID technological models. See Browser manual PDF for more details about how to use it.
Deprecated Features
BSAPI (C++ API) discontinued - ANNOUNCEMENT
We set the End of Life for BSAPI (our C++ API) for 2023-03-31 after
discussion with partners/customers, who actively gave us feedback on C++ API.
What does it mean for partners/customers?:
- Partners/customers with installed BSAPI version and valid Maintenance & Support can update to BSAPI v3.40.x (March 2021 release; x = latest) and ask for bug-fixes. BSAPI v.3.40.x to be bug-fixed in long-term (18+6 months (i.e., till 2023-03-31)) and BSAPI v3.45 was not released.
- New and existing partners can use Speech Engine (RESP API) or our command-line interface version (CLI/CMD) or GUI applications (Phonexia Browser or Voice Inspector).
End of Life for technical models
Several new technical models have been released. So in accordance with our Phonexia Product Support Lifecycle Policy, we announce the end of life for the following models:
| TECHNOLOGY | MODEL TO BE DEPRECATED | NOTE:LATEST MODEL |
|---|---|---|
| STT + KWS + PHNREC | EN4 English (United States) | EN_US_6 English (United States) |
| STT + KWS + PHNREC | HR_HR4 Croatian (Croatia) | HR_HR_6 Croatian (Croatia) |
Known Issues
Some of the important known issues we see and plan to work on:
- BROWSER: Only one VAD model presented even if multiple VAD models are available on SPE
- SPE: Preferred phrases work currently in CS_CZ_6 STT only - we will add it to other languages in upcoming updates
Release Plan for future
For the next public release, we plan to:
- Upgrade the Spanish model (technologies STT / KWS / PHNREC, the expected model name ES_ES_6) - improved accuracy expected.
- Add a new decoder and new VAD configuration to the existing STT technology model (i.e., languages in STT) - improved accuracy expected.
We also work hard on other products:
- Phonexia Voice Verify - a voice verification solution for contact centers to enhance the security layer.
- Phonexia Orbis - an on-premises software solution that enables the rapid investigation of audio recordings.
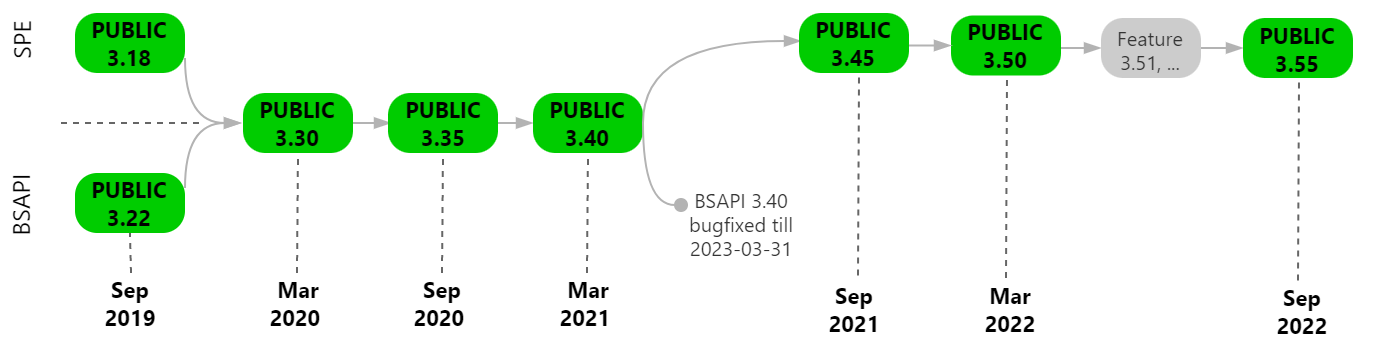
The next public release (v3.50) for the Speech Platform components (Speech Engine and Phonexia Browser) is planned for 2022-03-30. The diagram below shows the release plan.