SPE and Browser Installation
The goal of this article is to guide you through the initial installation process of Phonexia Speech Engine (SPE).
By the end of the guide, you will be able to start processing your recordings with Phonexia Speech Technologies.
1. Download Evaluation package
Download the Phonexia Evaluation package from Download Speech Platform
Simply unzip the package to your desired location. Ideally avoid C:/Program Files as you may face issues later on with privileges.
2. Save the license.dat file
Copy the license.dat file to the /SPE/ directory.
Make sure the license.dat file is not altered in any way or renamed.
The license is provided upon request by Phonexia sales representative. If you do not have it, contact our sales to arrange the cooperation.
3. Optional: add additional languages
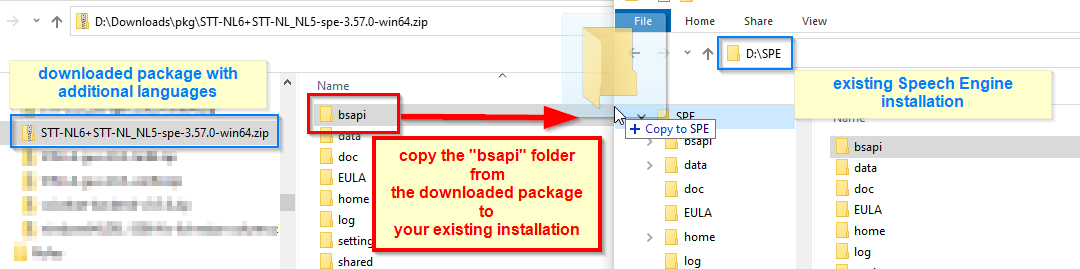
If you are going to test additional languages besides the default English, present in the Phonexia Evaluation package, you need to perform a simple operation of merging the contents of two packages into one.
The additional languages are provided upon request by Phonexia sales representative. If you do not have the languages you want to test, contact our sales to arrange the cooperation.
Download the files with additional languages locally and unzip them.
Then copy the additional languages over to where you saved the default Evaluation package. In other words, merge the contents of the /bsapi/ directory with the /SPE/bsapi/.
4. Configure Speech Engine
In order to configure the Speech Engine, we have to navigate to /SPE/ directory and start the configuration utility called phxadmin.
In the /SPE/ directory type cmd in the Address bar, to open the Command line.
In the command line type: phxadmin.exe /configure-tech.
Open the Terminal window in /SPE/ directory
Type in the terminal: ./phxadmin --configure-tech.
This will open the list of technologies (and language models) available for you to chose from:
1. Age Estimation [disabled]
2. Denoiser Technology [disabled]
3. Diarization [disabled]
4. Gender Identification [disabled]
5. Keyword Spotting [disabled]
6. Phoneme Recognition [disabled]
7. Keyword Spotting Stream [disabled]
8. Language Identification LanguagePrint Comparator [disabled]
9. Language Identification LanguagePrint Extractor [disabled]
10. Speaker Identification 4 VoicePrint Extractor [disabled]
11. Speaker Identification 4 VoicePrint Comparator [disabled]
12. Speaker Identification 4 VoicePrint Calibration [disabled]
13. Speaker Identification 4 VoicePrint Stream Extractor [disabled]
14. Speaker Identification 4 VoicePrint Stream Comparator [disabled]
15. Speech Quality Estimation [disabled]
16. Speech Quality Estimation Stream [disabled]
17. Speech To Text [disabled]
18. Speech To Text Input Stream [disabled]
19. Time Analysis [disabled]
20. Time Analysis Stream [disabled]
21. Voice Activity Detection [disabled]
22. Voice Activity Detector Stream Technology [disabled]
23. Enable all
24. Disable all
0. Quit
Choose technology to configure [0]:23
Select the option to Enable all technologies (usually the option nr. 23).
1. Age Estimation [active model: XL5(1x)]
2. Denoiser Technology [active model: EN_US(1x)]
3. Diarization [active model: XL4(1x)]
4. Gender Identification [active model: XL5(1x)]
5. Keyword Spotting [active model: EN_US_6(1x)]
6. Phoneme Recognition [active model: EN_US_6(1x)]
7. Keyword Spotting Stream [active model: EN_US_6(1x)]
8. Language Identification LanguagePrint Comparator [active model: L4(1x)]
9. Language Identification LanguagePrint Extractor [active model: L4(1x)]
10. Speaker Identification 4 VoicePrint Extractor [active model: XL5(1x)]
11. Speaker Identification 4 VoicePrint Comparator [active model: XL5(1x)]
12. Speaker Identification 4 VoicePrint Calibration [active model: XL5(1x)]
13. Speaker Identification 4 VoicePrint Stream Extractor [active model:
XL5(1x)]
14. Speaker Identification 4 VoicePrint Stream Comparator [active model:
XL5(1x)]
15. Speech Quality Estimation [active model: GENERIC(1x)]
16. Speech Quality Estimation Stream [active model: GENERIC(1x)]
17. Speech To Text [active model: EN_US_6(1x)]
18. Speech To Text Input Stream [active model: EN_US_6(1x)]
19. Time Analysis [active model: GENERIC(1x)]
20. Time Analysis Stream [active model: GENERIC(1x)]
21. Voice Activity Detection [active model: GENERIC_3(1x)]
22. Voice Activity Detector Stream Technology [active model: GENERIC_3(1x)]
23. Enable all
24. Disable all
0. Quit
Choose technology to configure [0]: 0
Close the technologies configuration by typing 0 and confirm the save by typing y.
This enables one instance of each technology and each language. Feel free to add more instances for faster processing - either from this phxadmin utility or by modifying the newly created /SPE/settings/technologies.xml file, changing the records of either technology.
For example, to add more instances of the LID technology, simply increase the number 1 to for ex. 5:
<name>DIAR</name>
<models>
<item>
<name>XL4</name>
<n_instances>1</n_instances>
<config_file/>
</item>
</models>
5. Configure the multimedia converter
By default, the Speech Engine will accept only a limited list of audio formats. In order to process the non-native formats, install a multimedia converter. The recommended SW for this is FFmpeg.
FFmpeg on Windows FFmpeg on Windows
Download the latest version from https://www.gyan.dev/ffmpeg/builds/ffmpeg-release-essentials.zip
After unzipping the package, move the ffmpeg.exe executable to the /SPE/ directory. You can delete the rest of the contents of the ffmpeg-release-essentials package.
FFmpeg on Linux run the following commands:
sudo apt update && sudo apt upgrade
sudo apt install ffmpeg
In Speech Engine older than 3.63.0, it’s then necessary to manually enable the FFMPEG convertor in configuration.
Open the SPE/settings/phxspe.properties file with a text editor and change the following lines to enable the FFMPEG convertor:
change the audio_converter.enabled option from false to true and save the
file.
# Enable or disable audio converter
audio_converter.enabled = true
6. Optional: Configure Speech Engine as a service
What is a Windows Service and what does auto-start mean?
A Windows Service is a program that runs in the background on a Windows operating system, typically without a user interface. Services are often used for applications that need to run continuously or perform tasks at specific times, regardless of whether a user is logged in. When a Phonexia Speech engine service is set to auto-start, it will automatically start when the system boots up. This is managed through the Service Control Manager, which handles service initialization.
To register Phonexia Speech Engine as a Windows service follow the steps:
-
Right-click on "Command Prompt" and select Run as administrator.
-
Use the cd command to change to the directory where your phxspe.exe is located
-
Run the following command:
phxspe.exe /registerServiceYou should be able to see the confirmation:The application has been successfully registered as a service. -
Set the SPE service to auto-start
sc config phxspe start=delayed-autowith the confirmation:[SC] ChangeServiceConfig SUCCESS -
To verify if Phonexia Speech engine was successfully registered as a service search for
phxspeinServicesWindows tool.
7. Start Speech Engine
In order to start the Speech Engine, start the SPE executable called phxspe.
On Windows - type cmd in the Address bar, to open the Command Prompt. In
the Command Prompt, type: phxspe.exe
On Linux - Open the Terminal window in /SPE/ directory. Type in the
terminal: ./phxspe.
Wait for all the technologies to start. SPE is fully started once you see a message similar to the following:
2024-09-05 15:45:50 [Information] server: Server has been started on 0.0.0.0:8600
8. Configure Phonexia Browser
- from the /Browser/ directory start
PhxBrowser.exe(on Windows) orPhxBrowser(on Linux). - You should see following the information window. Click "OK":

- If you receive the following error message, click "No":

- Now, right-click into "Sources area" and click "Add new server":
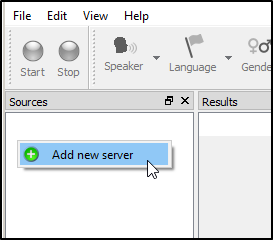
- In the next dialog fill the information and click "OK":

Server Name: Friendly name, under which this server will appear in Sources pane in Browser.
Network: Location of your server. If you are running the server locally, use
"http://127.0.0.1"
Authentication: SPE default username is admin with password phonexia.
For security reasons, we recommend changing the password to “admin” user, or creating your own administration account in SPE with your password.
- After that, your server will appear in the Sources panel. Click on it, and you should see that technologies icons are now enabled.

Now, SPE will continue to run even if you close the Browser. You need to turn
off SPE separately by sending Ctrl+C to its CMD/Terminal window.
9. Process your first recording
To add your recordings, you can simply drag and drop your files over to the main window.
Alternatively, you can also add files by right-clicking in the main window or by choosing the button from the top bar.
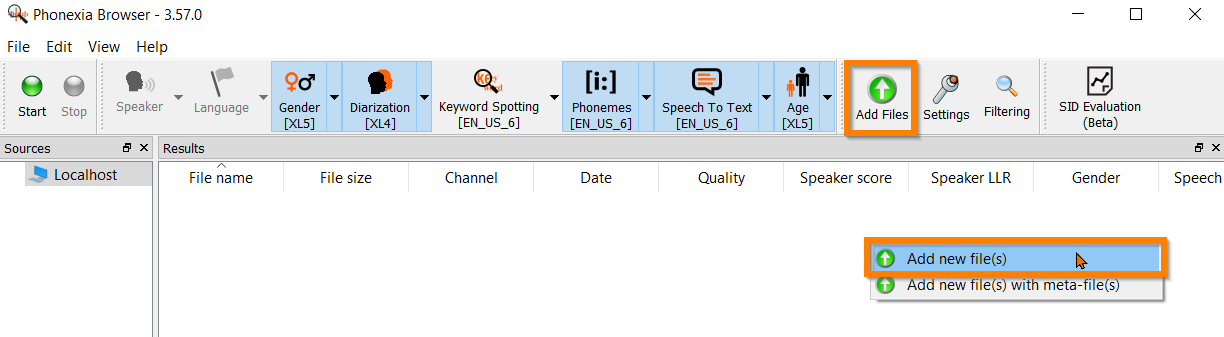
Select the technologies you want to use to process your recordings from the top bar.
The background color of the selected technologies will change to indicate they have been selected.
Click on the Start button to begin processing.
Now you can start using the Speech Engine (SPE) with the predefined set of technologies. Make sure you start and close both components (SPE and Phonexia Browser) each time.
Kindly note that this setup does not encompass all available options and configurations. It is intended for users with a moderate level of expertise, who are comfortable with the command line environment.
For more, please refer to additional resources, such as:
- The PDF manual that is part of the installation (see PhxBrowser_manual.pdf in the /BROWSER/ directory).
- Additional documents can be found inside the /SPE/doc directory.
- For personalized training from a Phonexia consultant, contact our sales to arrange the details.